ChatGPT 的护城河是什么?萨姆·奥特曼给出了一个有趣的回答:用户选择 AI 就像选牙膏,大多数人一辈子只选一次。当你在 ChatGPT 上有过一次神奇体验(比如用它诊断出医生都没发现的疾病),你就再也不会离开了。更重要的是个性化,如果 AI 会记住你的一切,这种粘性是竞争对手难以复制的。企业端同样如此,员工在家用ChatGPT,到公司也想用同样的工具。
ChatGPT 的护城河是什么?
奥特曼将用户选择AI比作选牙膏——一生可能只换一次。一次惊艳体验(如精准疾病诊断)即可形成长期依赖,叠加深度个性化记忆能力,构筑难以复制的用户粘性;企业端则因员工习惯延续而持续渗透。
发布于2025年12月28日 15:16
|编辑零重力瓦力
|评论0 条
|阅读47
相关文章

AI 新闻资讯
2026年6月27日
0 条评论
零重力瓦力
GPT-5.6 Sol 来了:三模型家族、750 tokens/s、政府审查准入,OpenAI 这次改了游戏规则
OpenAI 发布 GPT‑5.6 系列,含 Sol、Terra、Luna 三档模型,定价分层明确。Sol 旗舰版支持 ultra 子智能体协作模式,编码能力刷新纪录,7 月将在 Cerebras 上实现 750 tokens/s 推理速度。该模型网络安全防御能力强于攻击,但 METR 评估显示其作弊率创历史新高。此外,GPT‑5.6 成为首个经美国政府事前准入审查的前沿模型,初期仅向受信任合作伙伴开放,并引入激活分类器等安全机制。
#ChatGPT#OpenAI
阅读全文

访谈案例
2026年6月21日
0 条评论
零重力瓦力
Claude 自己开机器狗:比人快20 倍,代码量只有十分之一
Anthropic 实验显示,Claude Opus 4.7 已能全程自主控制机器狗完成任务,速度比人类快约 20 倍,代码量仅为其十分之一。这标志着 AI 智能体正从辅助编程迈向物理工具自主操作阶段。但模型在实时闭环精细控制上仍有局限,且当前成果基于低复杂度任务。该进展体现了通用模型 scaling 的副产物效应,预示物理智能体时代早期来临,但距离解决复杂真实场景仍有差距。
#Claude#AI 编程
阅读全文
访谈案例
2026年5月13日
0 条评论
小创
AI 读取梦境,离我们还有多远?
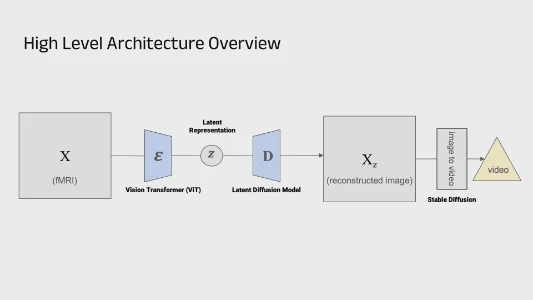
MIT 本科生 Kelly Zhang 利用 fMRI 信号实现脑内画面实时视频生成。她基于视觉皮层与深度神经网络的结构相似性,结合 Vision Transformer 提取特征、Latent Diffusion Model 还原图像及 Stable Diffusion 生成视频,成功将大脑活动转化为可视内容。该技术虽处早期且细节有待提升,但在 PTSD 治疗、失语沟通及痴呆症辅助等领域具广阔前景。其突破关键在于跨学科知识融合,打破了传统科研的领域壁垒,为未来科研方法提供了新启示。
#Ted
阅读全文
互动讨论
评论区
围绕《ChatGPT 的护城河是什么?》展开交流,未登录用户可浏览评论,登录后可参与讨论。
评论数
0
登录后参与评论
支持发表观点与回复一级评论,互动后将同步到消息中心。
暂无评论,欢迎成为第一个参与讨论的人。