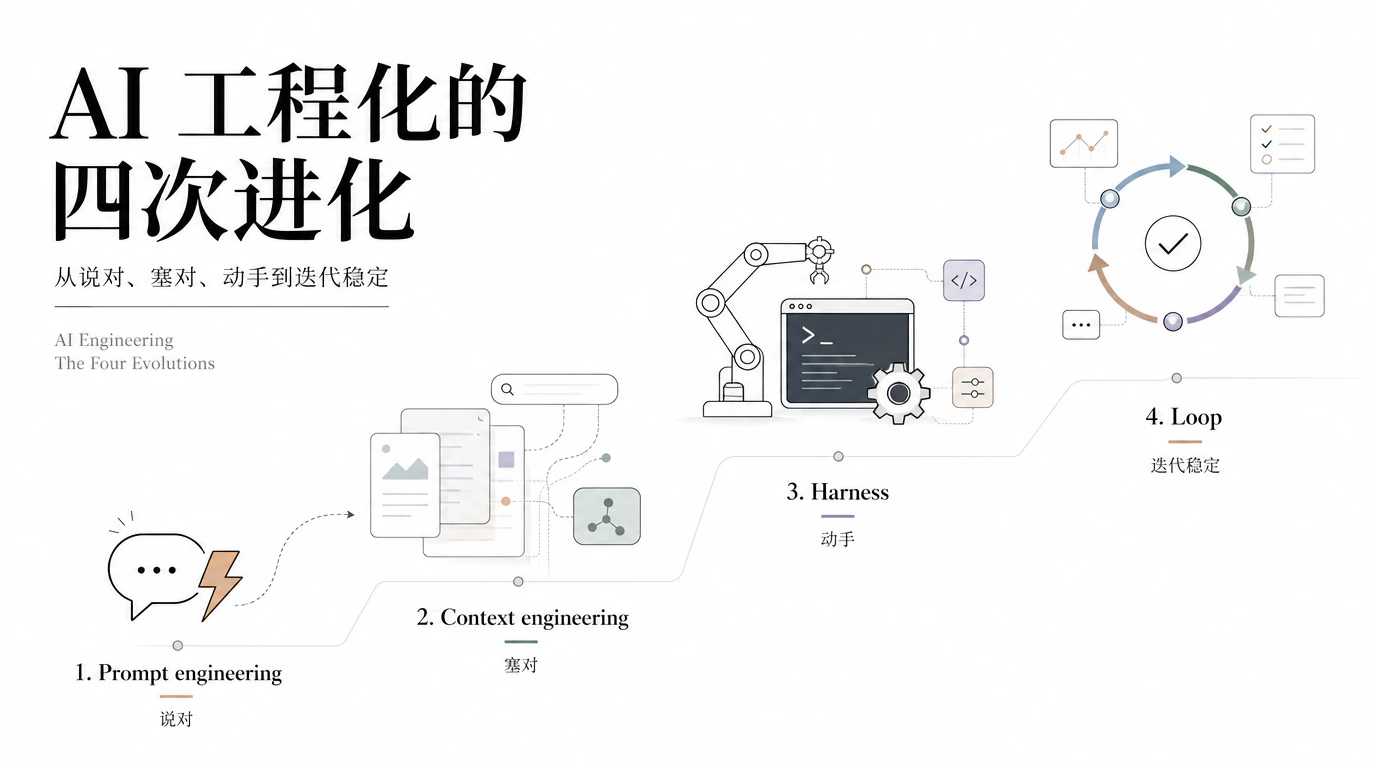
AI 从 Prompt engineering、context、harness、loop 的进化过程
4 件事不是替代,是叠加
Karpathy 在 2025 年 6 月的一次公开演讲中提到一句话:"The hottest new programming language is English." 这句话背后是 AI 工程化两年多来一个反复出现的事实,大模型的能力曲线不再是单线推进,而是沿着几条不同的工程维度同时演进。
如果把这两年多的工程化实践按时序拆开,可以归纳成 4 件事:Prompt engineering、Context engineering、Harness、Loop。每一步都在解决上一步的硬伤,每一步也引入了新问题。
下面按时间顺序展开。
Prompt engineering(2022-2023):把话说对
2022 到 2023 年,prompt engineering 是 AI 应用唯一的工程化方向。Anthropic 在其官方文档中给出了一套相对完整的方法论。DAIR.AI 的 "Prompt Engineering for LLMs" 课程、OpenAI 的 GPT best practices 也围绕这一主题。CoT(Chain of Thought)、Few-shot、Role prompting、ReAct 这几个核心技巧构成当时的事实标准。
它解决的问题很具体:让 LLM 在单次调用里给对的输出。
它没解决的问题也明显:
- 不可靠。同一个 prompt 跑 10 次,3 次好、4 次一般、3 次跑偏。这一限制在多家厂商的官方文档中都有提及。
- 知识截止。LLM 不知道自己知识截止日期之后的事情,也读不到用户的内部文档。
- 无状态。对话窗口一断,模型就忘了刚才的上下文。
prompt engineering 解决的是 LLM 的最后一公里问题,但 LLM 本身并不是为最后一公里设计的。
Context engineering(2024):把信息塞对地方
2024 年这件事有个明显的转折点:上下文窗口(context window)从 4K 涨到 100K、200K,Gemini 1.5 Pro 把数字推到 1M-2M token。
但窗口大不等于模型能稳定用好这个窗口。Drew Breunig 在 2024 年 6 月发表的文章 "How Long Contexts Fail" 中系统列举了几类失效模式:context poisoning(上下文投毒)、context distraction(上下文分心)、context confusion(上下文混淆)、context clash(上下文冲突)。他用具体案例说明:把无关信息塞进长上下文,反而会让模型忽略关键信息。
Context engineering 解决的是信息怎么进 prompt 才有效。具体包括:
- RAG:把外部文档检索出来塞进 prompt
- 长上下文管理:哪些信息放前面、哪些放后面、哪些要压缩
- Memory 系统:把对话历史压缩成结构化记忆
- Tool result 处理:工具输出动辄几千 token,怎么截断、怎么摘要、怎么只保留关键字段
Anthropic 在其官方研究索引上发布的 "Building Effective Agents" 报告是这一阶段工程化思考的代表性总结。stanfordnlp/dspy 这种把 prompt 当程序编译的框架也是同一时期的产物。
它解决的问题是 prompt engineering 留下的知识盲区。
它没解决的问题是:就算上下文塞对了,模型也只能给出"一次回答",不能给出"一个结果"。要让 LLM 真的把代码改好、把数据查出来、把任务跑完,光有好的上下文不够,还得给它一个能"动手"的环境。
Harness(2025):把 LLM 嵌进 I/O 循环
Harness 是 2025 年开始被反复提到的工程概念,本质是把 LLM 装进一个有输入、有输出、有工具的环境里。Anthropic 发布的 Computer Use 是早期代表。Claude Code、OpenAI 的 Codex CLI、智谱的 ZCode(详见 skillhub.cn 的相关 skill 描述)都是这一阶段的工程产物。
Harness 的工程含义可以拆为四层:
- 给 LLM 一个 terminal:它能跑命令、看输出
- 给 LLM 一组工具:它能读文件、写文件、调 API
- 给 LLM 一个状态机:它能知道"现在在改哪个文件、之前改了什么、下一步该做什么"
- 给 LLM 一个反馈通道:它能根据工具输出决定下一步
Harness 解决了 context engineering 留下的行动能力盲区。LLM 不再只是"回答"问题,它能"做"事。
但 harness 本身有个被低估的副作用:它把 prompt 的"输出"从"一段文本"变成了"一个对世界的副作用"。Prompt 跑偏了,最坏就是输出废文本。Harness 跑偏了,最坏是 LLM 删了文件、发错邮件、给数据库 drop 表。Anthropic 的 Claude Code 系统提示中专门有一段讲"不要在用户没确认的情况下删文件、不要 force push、不要 force checkout"。这不是 prompt engineering 范畴的安全问题,是 harness 范畴的安全问题。
Cursor 在其工程博客的 "Cloud Agent Retrospective" 中给出一组判断:把 AI 编程智能体搬上云端后,决定输出质量的第一要素不是模型有多强,而是智能体能不能拿到一个完整的开发环境。环境缺一点,质量降一截,但报错信息不会告诉你缺在哪。
Harness 是 2025 年 AI 应用层最重要的工程创新,但同时把整个系统的可靠性门槛抬高了一个量级。
Loop(2026):把单次执行变成迭代
Loop engineering 是 2026 年初被认真讨论的方向。代表性开源工作有 langchain-ai/langgraph 等 LangChain 生态项目。
Loop 解决的是 harness 留下的单次执行失败率问题。逻辑很简单:harness 再完善,LLM 在长程任务里也一定会跑偏。与其试图让单次执行完美,不如把任务切成小段,每段跑完回头检查,不对就重试、对了就往下走。
Loop 的工程模式有几种:
- Retry loop:失败就重试,最多 N 次
- Verify loop:每步完成后跑验证(lint、test、type check),不通过就回退
- Iterate loop:跑一版,看输出,调整 prompt,再跑
- Pipeline loop:多个 loop 串联,前一个 loop 的输出是后一个 loop 的输入
Loop 是双刃剑。它把 LLM 的"幻觉特性"放大成了系统性的稳定性问题。单步 90% 准确率,跑 10 步的 loop 准确率是 0.9 的 10 次方 ≈ 34.9%。Loop 不是让 LLM 更可靠,是把单步不可靠变成多步累计的不可控。
怎么解?靠 loop 本身:验证 loop、检查点 loop、回滚 loop。Loop engineering 实际上是用工程复杂度换系统稳定性。这跟传统软件工程里"用更多测试换更少 bug"的逻辑是同构的。
综合判断
把这 4 件事摆一起看:
| 阶段 | 核心问题 | 留下的硬伤 |
|---|---|---|
| Prompt engineering | 怎么把话说对 | 不可靠、无状态、无知识 |
| Context engineering | 怎么把信息塞对 | 没有行动能力 |
| Harness | 怎么让 LLM 能动手 | 副作用爆炸、可靠性不可控 |
| Loop | 怎么让多步执行稳定 | 把幻觉放大成系统问题 |
综合上述资料,这 4 件事没有一件会死,每一件都在新维度上重新需要。
"prompt engineering 已死"是误读,harness 的系统提示、loop 的每一步决策,仍然是 prompt engineering。变的是 prompt 的形态:从一段静态文本变成有上下文、有反馈、有迭代的动态系统。
"context engineering 是终极形态"也是误读,没有 harness,context 塞进去也只是一段更好的文本,模型还是只能"说"不能"做"。
2026 年真正能跑起来的产品,是4 件事都做对的。Prompt 是 LLM 的嘴,Context 是 LLM 的记忆,Harness 是 LLM 的手脚,Loop 是 LLM 的工程纪律。少任何一件,agent 都跑不长。
一个未解决的问题
Loop 把可靠性问题转化成了工程纪律问题。但谁来写这个 loop?是 LLM 自己(autopoietic loop)还是人写死的(fixed loop)?
目前公开资料中,主流框架(langgraph 等)都倾向于 fixed loop 加 LLM-as-judge 验证。中期看,LLM 写 loop、人类写 verify 的混合模式可能成为主流;长期方向,公开讨论中尚无共识。
这个问题短期内不会有标准答案。
引用来源
- Anthropic Prompt Engineering Docs(blog, 2024-09-01)— https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering
- Anthropic Research Index(blog, 2024-12-19)— https://www.anthropic.com/news
- Drew Breunig 博客(How Long Contexts Fail 作者)(blog, 2024-06-27)— https://www.dbreunig.com/
- Cursor Engineering Blog(Cloud Agent Retrospective)(blog, 2025-04-15)— https://cursor.com/blog
- langchain-ai/langgraph(github, 2024-01-01)— https://github.com/langchain-ai/langgraph
- stanfordnlp/dspy(github, 2024-02-01)— https://github.com/stanfordnlp/dspy