
Gemini 2.5 Flash Image(又名 nano-banana),是 Google 目前最先进的图像生成与编辑模型。本次更新能够让用户将多张图片融合为一张,保持角色形象的一致性,实现丰富的叙事,用自然语言实现定向编辑,并利用 Gemini 的世界知识生成和编辑图片。
在今年早些时候 Google 首次在 Gemini 2.0 Flash 上推出原生图像生成功能时,用户普遍表示很喜欢它的低延迟、性价比高、易于使用。但也希望图片质量更高、创作控制力更强。
现在,这款模型已通过 Gemini API 与 Google AI Studio 向开发者开放,同时还可在 Vertex AI 企业平台使用。Gemini 2.5 Flash Image 的价格为每 100 万输出 token 30美元,每张图片为 1290 输出 token(即每张图片约0.039美元)。其余输入输出方式均遵循 Gemini 2.5 Flash 的定价。
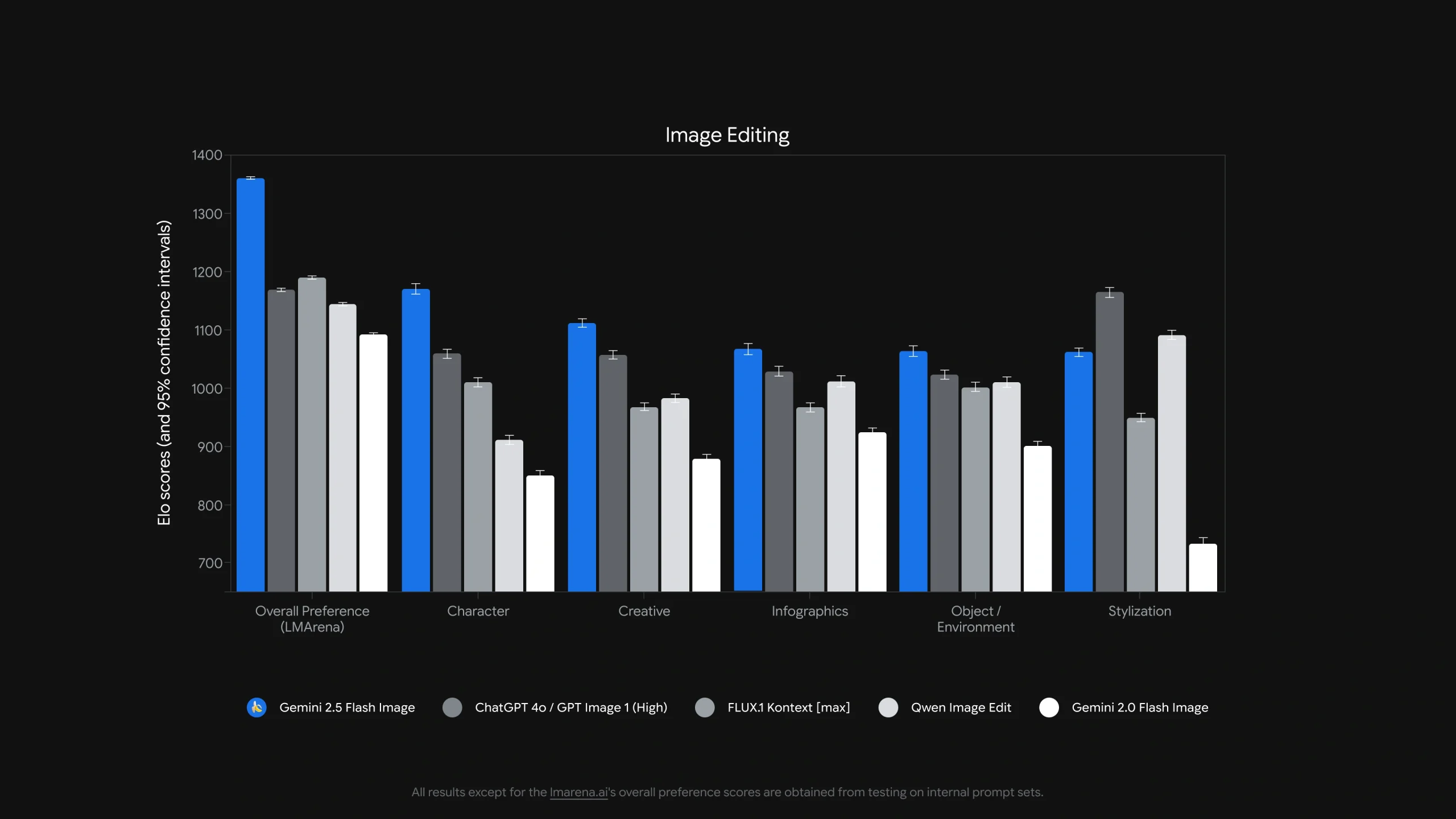
(lmarena 结果来自:https://lmarena.ai/leaderboard)Gemini 2.5 Flash Image 实际应用
为了让 Gemini 2.5 Flash Image 的开发体验更轻松,Google 对 Google AI Studio “构建模式”进行了重大更新(后续还有更多更新)。在下面的示例中,你不仅可以快速测试模型能力,还可以通过自定义 AI 应用进行 remix,只需一句提示词就能实现你的想法。准备好后,你可以直接从 Google AI Studio 部署你的应用,或将代码保存到 GitHub。
你可以尝试这样的提示词:“为我构建一个图片编辑应用,允许用户上传图片并应用不同滤镜”,也可以选择预设模板进行 remix,这一切都是免费的!
角色一致性
在图像生成领域,一个核心挑战是让同一个角色或物体在多次生成和编辑中保持外观一致。现在你可以让同一个角色出现在不同环境里,将同一产品从多个角度在新场景中展示,或为品牌生成风格统一的视觉资产,且都能准确保留主体形象。
Google AI Studio 内已经有了一个模板应用(你可以轻松自定义并基于它扩展代码),来展示角色一致性的能力。
除了角色一致性外,模型在遵循视觉模板方面表现也很优秀。开发者已经在探索如房产卡片、员工证件照、产品目录动态 mockup 等多种案例,都可以基于同一个设计模板批量生成。

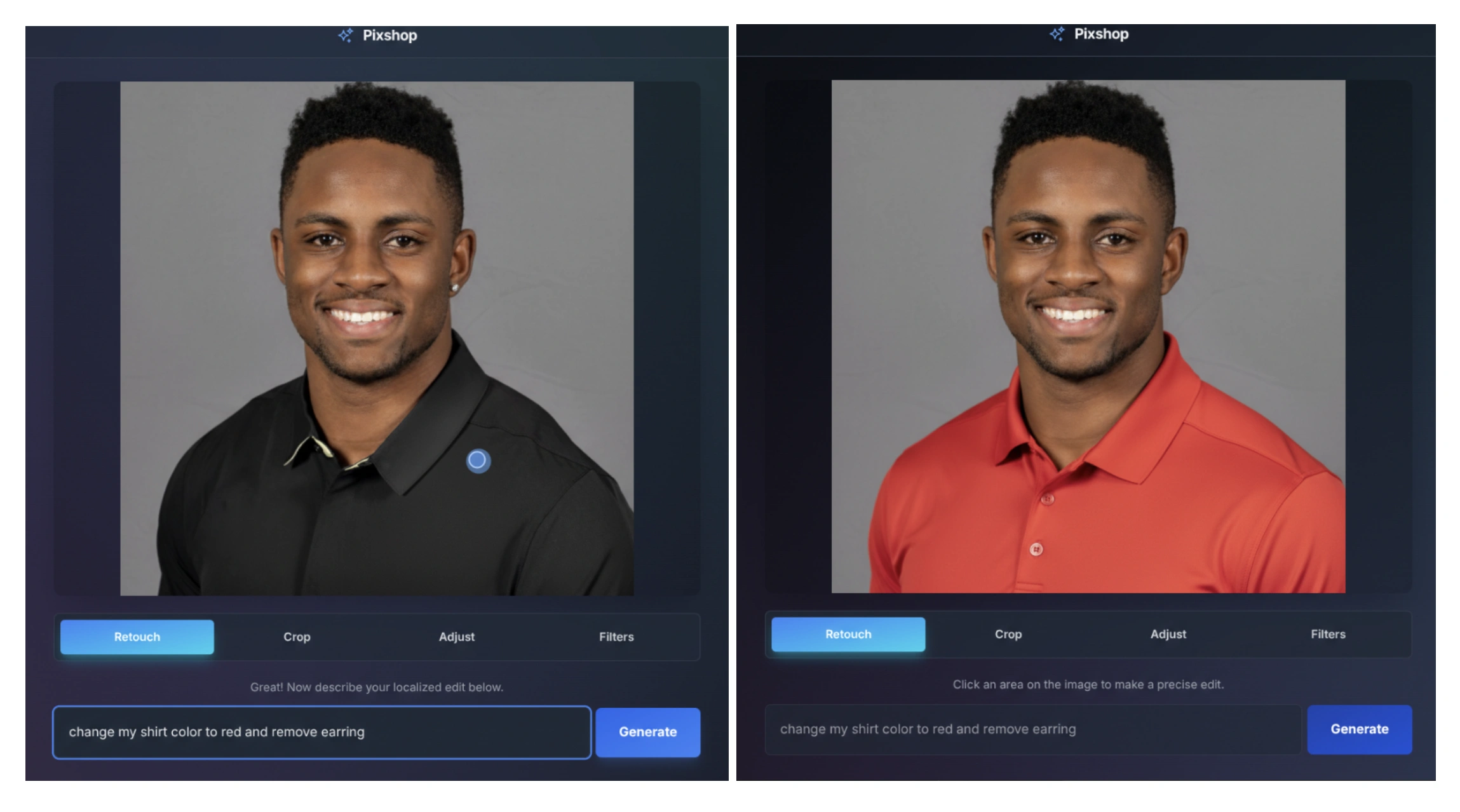
基于提示词的图片编辑
Gemini 2.5 Flash Image 支持用自然语言进行定向、精细的图片编辑。例如,你可以让模型模糊背景、去除T恤污渍、从照片中移除某个人、调整姿势、为黑白照片上色,甚至更多,只需一句提示。
AI Studio 还内置了一个图片编辑模板应用,支持界面操作和提示词编辑两种方式。
原生世界知识
以往的图片生成模型虽然美学表现出色,但对真实世界的语义理解有限。Gemini 2.5 Flash Image 利用 Gemini 的世界知识,带来了全新用途。
为此,Google 做了一个 Google AI Studio 模板应用,可将画布变成互动教育助手。它能读懂手绘图,帮助解答现实问题,支持复杂编辑指令一步执行。
多图片融合
Gemini 2.5 Flash Image 能理解并融合多张输入图片。你可以将一个物体放进新场景,为房间更换色彩和材质风格,或者一句话融合多张图片为一体。
Google 在 Google AI Studio 内为此制作了一个多图片融合模板应用,让你拖拽产品到场景中,快速生成新的真实感融合图片。
立即开始构建
大家可参考 开发文档,立即用 Gemini 2.5 Flash Image 进行开发。该模型目前通过 Gemini API 和 Google AI Studio 提供预览版,几周后将进入稳定版。上面展示的所有 Demo 应用都是在 Google AI Studio 里 “vibe coding” 出来的,支持用提示词 remix 和自定义。
OpenRouter.ai 已与 Google 合作,将 Gemini 2.5 Flash Image 带给全球 300 万开发者。这是 OpenRouter 上第一个可生成图片的模型(目前已有480多个模型上线)。
Google 还与领先的生成式媒体开发平台 fal.ai 合作,让更广泛的开发社区也能使用 Gemini 2.5 Flash Image。
所有由 Gemini 2.5 Flash Image 创建或编辑的图片,都会嵌入不可见的 SynthID 数字水印,确保图片可被识别为 AI 生成或编辑。
Python 示例代码
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client()
prompt = "Create a picture of my cat eating a nano-banana in a fancy restaurant under the gemini constellation"
image = Image.open('/path/to/image.png')
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt, image],
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = Image.open(BytesIO(part.inline_data.data))
image.save("generated_image.png")
原文链接
Introducing Gemini 2.5 Flash Image, our state-of-the-art image model


