在 AI 领域,越来越多的公司试图挑战巨头的垄断地位,杭州深度求索作为国内的一家 AI 初创公司,凭借其全新开源模型 DeepSeek-V3,成功吸引了全球的目光。这款被称为 “开源领域最强挑战者” 的模型,不仅性能媲美顶尖闭源 AI,还在成本和效率上实现了突破。让我们一起来看看这匹 “黑马” 是如何改变游戏规则的。
用更少的资源实现更强的性能
DeepSeek-V3 的亮点之一,是其在有限资源下的强悍表现。DeepSeek 凭借突破性的优化技术,成功用 2048 张 Nvidia H800 GPU,仅耗时两个月,就训练出了拥有 6710 亿参数的超大规模模型。而这一训练成本仅耗费 550 万美元,相比之下,OpenAI 的 GPT-4 和 Meta 的 Llama-3.1 的训练成本高达数亿美元。
根据 DeepSeek 的研究团队介绍,他们通过一系列创新技术实现了这一目标。例如,模型使用了混合专家(MoE)架构,在具体任务中只需激活 37 亿参数,从而大幅降低算力和内存需求。此外,团队开发了“双管道”(DualPipe)算法,优化了计算和通信的并行效率,使模型在训练过程中几乎消除了通信瓶颈。更先进的是,他们还采用了 FP8 低精度计算框架,不仅提升计算速度,还减少了内存占用,同时保证了训练的稳定性。
这一切让 DeepSeek-V3 完成了与 Meta Llama 3.1 同等规模的模型训练,而消耗的算力仅为 Llama 3.1 的 1/11。这对于资源有限的团队来说无疑是一个巨大的激励。
性能媲美闭源巨头,开源推动平等竞争
DeepSeek-V3 的性能也令人印象深刻。在多个基准测试中,该模型超越了许多开源对手(如 Meta 的 Llama-3.1 和 阿里巴巴的 Qwen 2.5),甚至在某些任务上接近甚至超越了闭源模型(如 OpenAI 的 GPT-4o 和Anthropic 的 Claude 3.5)。例如,在代码生成领域的 Codeforces 竞赛中,DeepSeek-V3 的表现力压群雄。而在数学和中文语言处理等任务中,其得分更是创造了新高,比如在 Math-500 测试中拿下了 90.2 的高分,远远领先于其他开源模型。
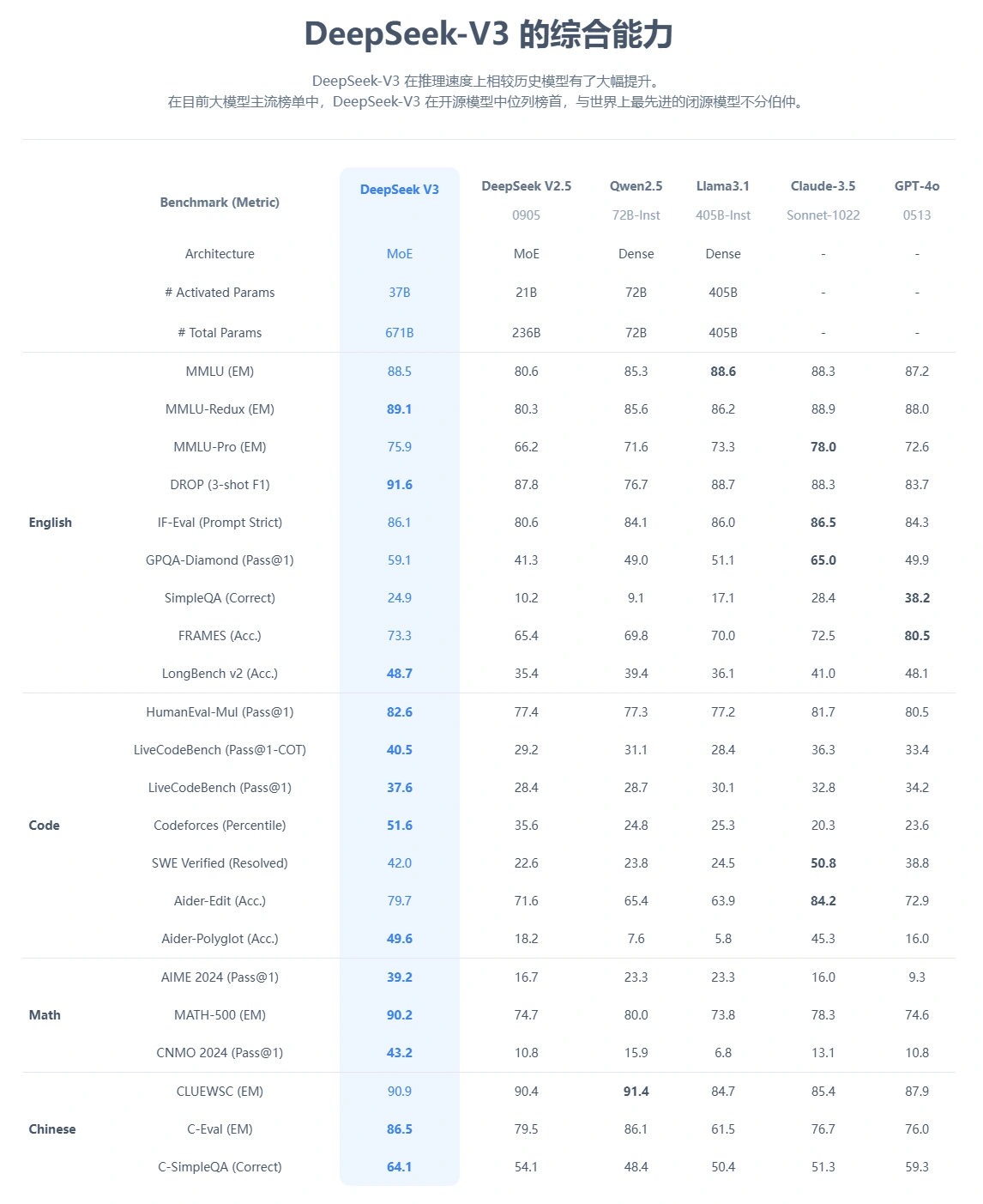
在多个基准测试中,DeepSeek-V3 的得分都超过了其他主流模型更重要的是,DeepSeek 选择将这一模型开源,开发者可以免费下载并用于商业用途。借助 Hugging Face 平台,企业还可通过 API 轻松接入这一强大的 AI 工具。相比那些只能通过 API 付费访问的闭源模型,DeepSeek-V3 的透明性和开放性无疑降低了进入 AI 技术的门槛。
技术与限制并存的现实考验
尽管 DeepSeek-V3 展现了强大的能力,但它并非没有挑战。首先,由于模型体积庞大,其推理和部署仍需高端硬件支持,这可能对资源有限的小型企业形成一定的门槛。此外,DeepSeek 的团队也承认,尽管他们的 “双阶段推理” 策略将生成速度提升了两倍,但仍有进一步优化的空间。
另一个值得注意的问题是,作为一家国内公司,DeepSeek-V3 的部分输出可能受到特定政策的约束。例如,在涉及敏感话题时,模型可能会回避作答,这可能会影响其在全球范围内的适用性。
开源AI的未来:挑战与机遇并存
DeepSeek-V3 的发布不仅仅是技术上的突破,它还代表了开源 AI 领域的一次重要里程碑。在过去,AI 行业一直由少数几家巨头主导,而 DeepSeek 这样的新兴力量正在打破这一格局。通过提供性能强大、成本低廉的开源模型,DeepSeek 为全球开发者和企业带来了更多选择,同时也在推动 AI 技术的普及化。

DeepSeek-V3 的使用价格也十分有优势,每百万输出 Token 仅需2元未来,随着更先进硬件的出现以及算法的持续优化,像DeepSeek-V3 这样的模型可能会进一步缩小开源与闭源之间的差距。而这场关于开放性与垄断的较量,也将为整个行业注入更多的活力。
总之,DeepSeek-V3 不仅重新定义了开源 AI 的可能性,也为那些希望在 AI 领域实现创新的小型团队打开了一扇新的大门。对于整个 AI 行业来说,这或许只是一个开始。
参考链接
- DeepSeek 官方网站
- DeepSeek’s new AI model appears to be one of the best ‘open’ challengers yet
- Chinese AI company says breakthroughs enabled creating a leading-edge AI model with 11X less compute — DeepSeek's optimizations could highlight limits of US sanctions
- DeepSeek-V3 Sets New Benchmark as an Open-Source AI Model