资讯标签
#ReAct
AI 产品工具
2025年4月18日
0 条评论
零重力瓦力
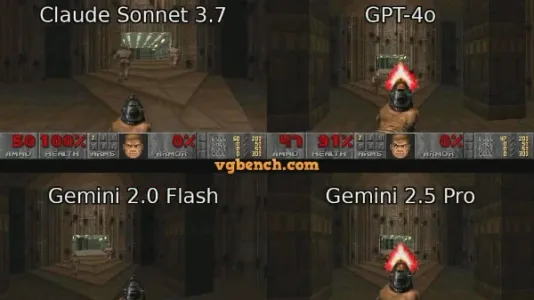
VideoGameBench: AI 模型游戏智能的基准测试
普林斯顿大学推出VideoGameBench基准,涵盖20款GB/MS-DOS经典游戏,专测视觉-语言模型在真实游戏环境中的理解、推理与操作能力;Lite版本支持暂停游戏以缓解响应延迟。实验表明,当前VLM在目标导向性、动作精度及机制理解上仍存在明显短板。
#智能体#多模态#ReAct
阅读全文

AI 教程知识
2025年4月7日
0 条评论
零重力瓦力
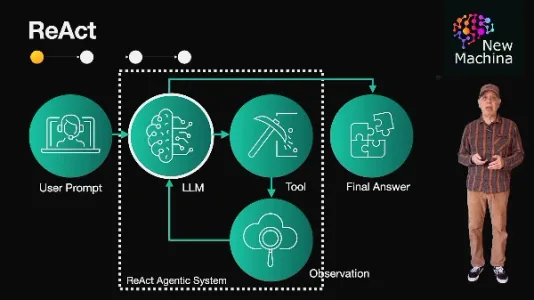
智能体 RAG:大语言模型应用的新模式
智能体RAG突破传统RAG一次性检索的局限,让大模型具备“推理-行动”能力:可基于初步结论动态调用检索工具、跨源交叉验证,实现多轮查证与迭代思考,显著提升回答的全面性与准确性。
#RAG#ReAct#New Machina
阅读全文
AI 教程知识
2025年3月14日
0 条评论
零重力瓦力
深入解析 LangGraph 智能体开发工作流:从概念到实践
LangGraph 通过图结构实现 ReAct 智能体工作流,让 LLM 能动态调用 NOAA 浮标 API 获取实时海洋天气数据。示例中,模型自主推理浮标 ID 并调用工具,展现“推理+行动”能力,代码简洁、扩展性强,为金融、医疗等需实时数据的场景提供可落地的智能体开发路径。
#智能体#ReAct#New Machina
阅读全文
AI 教程知识
2025年3月10日
0 条评论
零重力瓦力
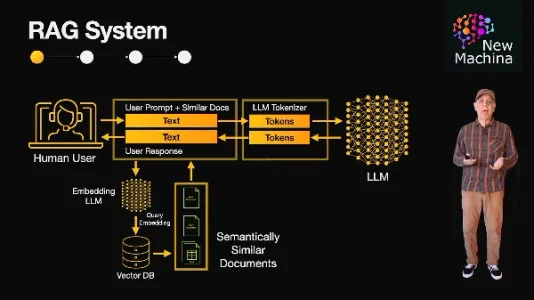
RAG 与 ReAct:两种提升大语言模型能力的关键方法
RAG通过向量检索外部知识提升回答准确性,适合专业领域问答;ReAct让模型边推理边调用工具,擅长多步骤复杂任务。二者分别拓展知识广度与推理深度,可独立使用或协同集成,是构建实用AI应用的关键路径。
#RAG#ReAct#New Machina
阅读全文
AI 教程知识
2025年3月3日
0 条评论
零重力瓦力
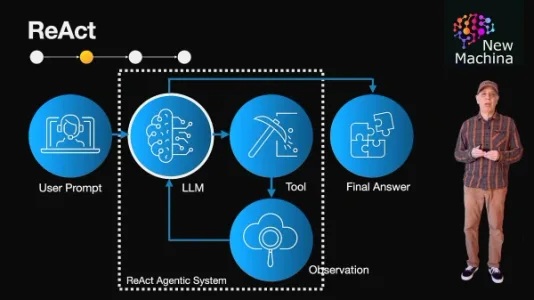
ReAct:让语言模型学会思考与行动
ReAct框架让大模型不再只被动回答问题,而是能自主推理、调用API获取实时信息、观察结果并迭代优化——比如查询圣克莱门特海岸浪况时,主动调用气象浮标接口,而非依赖过时训练数据。它标志着AI正从“问答器”迈向“问题解决者”。
#ReAct#智能体#New Machina
阅读全文