经常写文章、翻译文章的朋友一定会遇到这样的情况,文章中中英文格式的标点、表达混杂在一起。尤其在切换输入法的时候,会搞不清楚全角和半角的标点符号。市面上也没有好的中文格式检查和优化工具。
于是自己动手 vibe coding 了一个,主要功能如下:
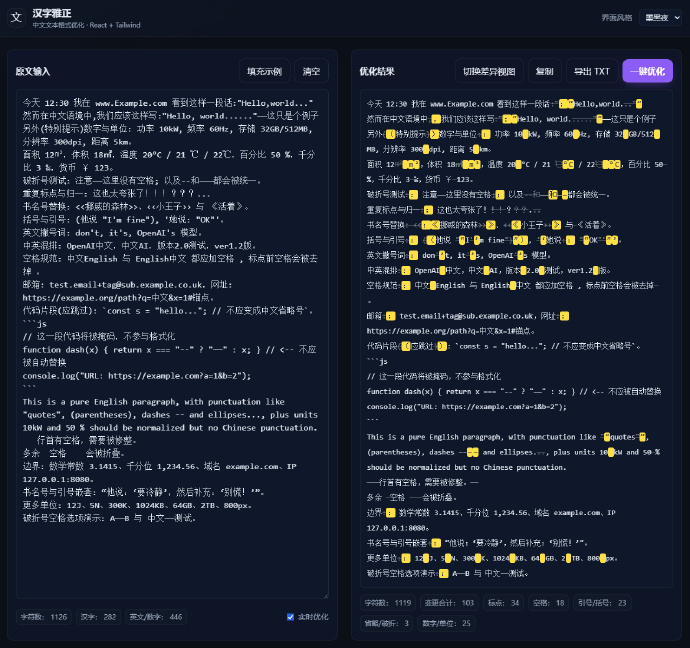

- 中文标点全角化:自动将中文环境下的英文标点(如 . , ; : ! ?)替换为全角中文标点(如 。 , ; : ! ?)。
- 括号全角化:在中文或非字母数字环境下,将半角括号 () 替换为全角括号 ()。
- 引号与撇号修复:自动配对英文引号为中文引号("abc" → “abc”),撇号 ' 在英文词内保留,其它情况成对替换为中文单引号。
- 书名号归一:将所有尖括号类的书名号(如 <<书名>>、‹‹书名››)统一为中文《书名号》。
- 破折号与省略号统一:多种破折号(--、––、——等)统一为 ——,多种省略号(...、……等)统一为 ……。
- 重复标点归一:连续的标点(如 !!?、、、、、)自动折叠为单个。
- 空格规范:自动添加中英文、数字与中文之间的空格(如 Qwen 模型、版本 2.0)。 删除标点前多余空格,修正括号内外空格。连续空格折叠为一个。
- 数字与单位格式:单位与数字间自动规范空格和格式(如 10 kW、60 Hz、32 GB、512 MB、300 dpi 等)。百分号/千分号紧贴数字(如 50%、3‰)。温度符号支持 ℃ 和 °C,自动归一。平面/体积单位规范(如 ㎡ → m²,㎥ → m³)。货币符号(如 ¥123)自动去除中间空格。
- 代码块、链接、邮箱自动跳过:保护三引号代码块、行内代码、URL、邮箱,不参与任何格式替换。
- 英文段落识别:自动判断纯英文行,不做中文标点全角化处理,其他规则仍生效。
- 全文修剪:每行首尾空白自动去除,连续空行压缩为最多两行。
APP 会高亮所有修改的内容,便于作者检查。
评论(0)