DeepSeek 发布了一款超强的开源 OCR 模型:DeepSeek-OCR。这个模型不仅可以用来识别图片中的文字,对超长文本处理也给出了一个新的思路。
由于,在处理超长文本内容时,大模型一直面临一个难题,文本越长,计算资源消耗得越快。DeepSeek-OCR 的出现,尝试了一个很新颖的解决思路,把长文本 “拍成一张图”,再用视觉模型来压缩和还原信息,相当于用图片来 “打包” 文字,让处理变得更加高效。
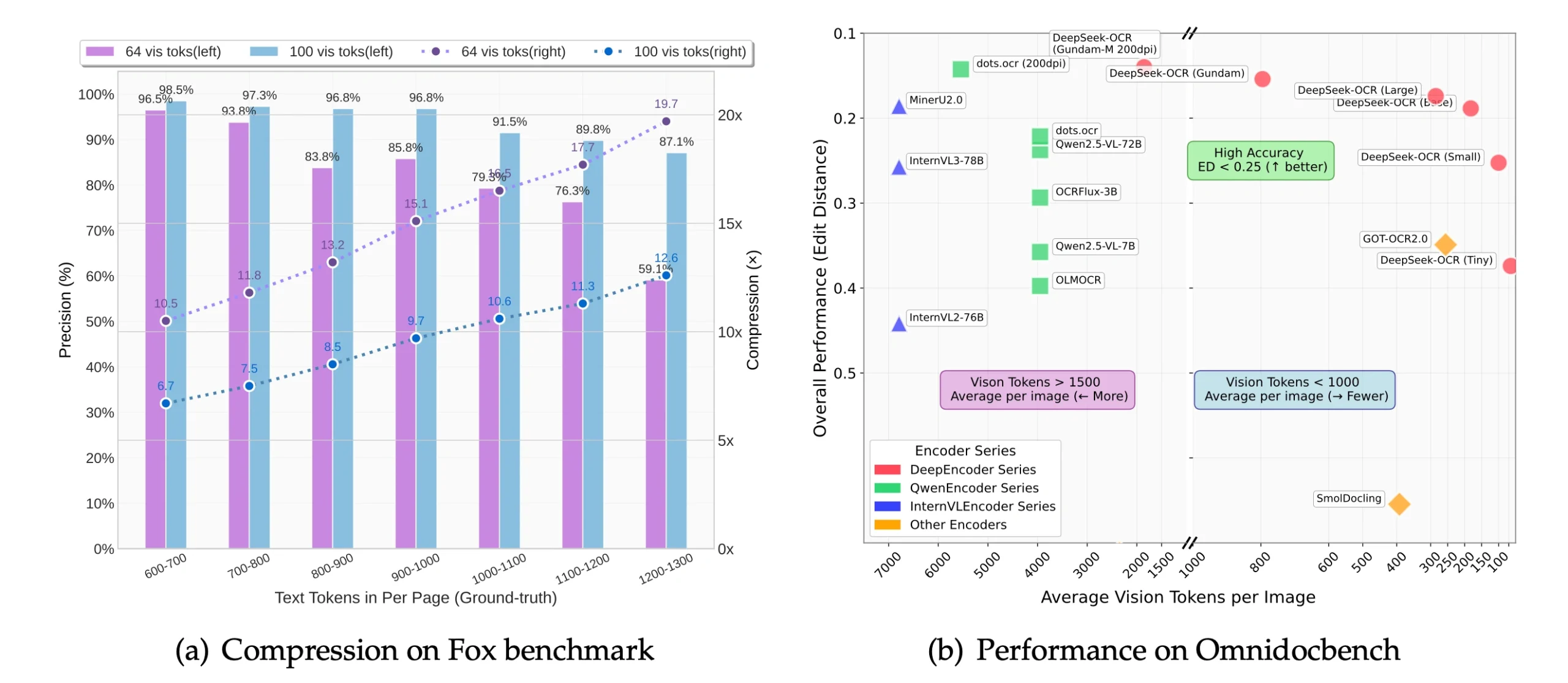
DeepSeek-OCR 其实就是一个视觉语言模型,核心思路是,输入一张包含大量文本的图片,用自研的视觉编码器(DeepEncoder)把图片压缩成尽可能少的 “视觉 Token”,然后通过解码器把这些 Token 恢复成原始文本。实验里,这种方法能把文本 Token 压缩 10 倍以上,还能保持 97% 的还原精度。即使压缩到 20 倍,准确率也有 60% 左右。这意味着,未来在处理超长历史对话、巨量文档时,有望极大减少内存和计算消耗。
DeepSeek-OCR 在技术上有不少亮点:
1. 超高压缩比:常规视觉语言模型面对高分辨率图片时,通常会生成大量视觉 Token,计算、存储都很吃力。DeepSeek-OCR 的 DeepEncoder 用了分阶段窗口注意力、卷积压缩和全局注意力的结合,把视觉 Token 数量控制得很低。例如,原本一页文档有 1000 个文本 Token,用 100 个视觉 Token 就能还原,压缩比高达 10 倍。
2. 多分辨率兼容:模型不仅能处理小尺寸图片,也能兼容高分辨率输入,甚至可以用拼贴的方式处理报纸这类超大页面。这让它在实际应用中非常灵活,适合各种文档场景。
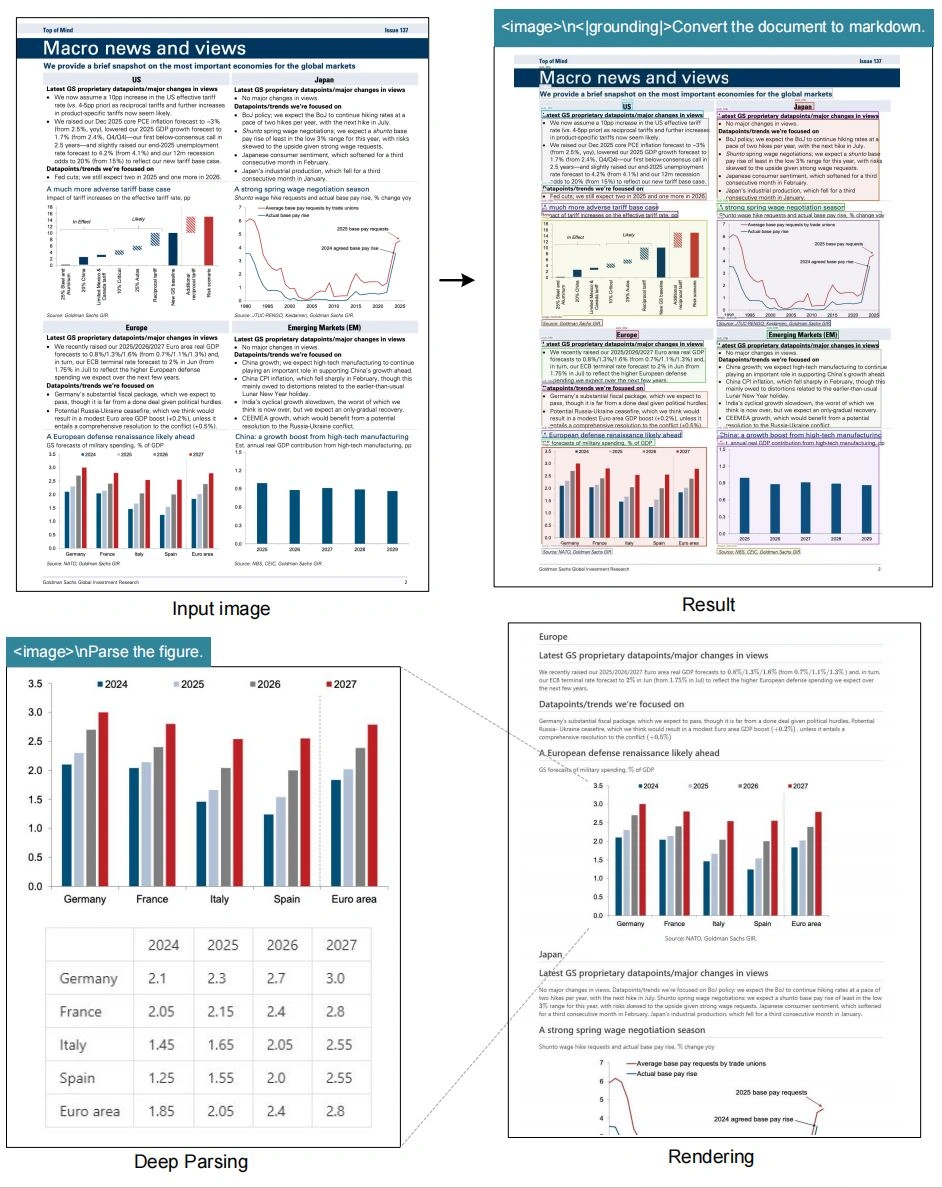
3. 端到端设计:不像传统 OCR 需要先检测文字框、再识别字符,DeepSeek-OCR 直接用一套模型做 “图片到文本” 的映射,还能解析图表、化学式、几何图形等复杂元素,支持 Markdown、HTML 等多种格式输出。
4. 极强的生产能力:模型推理效率高,单张高性能显卡一天能生成 20 万页以上的训练数据,非常适合大规模数据生产,为大模型预训练提供了基础。
5. 多语言覆盖和泛视觉能力:数据集覆盖了近百种语言,模型既能做高质量的中文、英文 OCR,也能识别小语种,还具备一定的图片描述、检测等视觉理解能力。
6. 对 “遗忘机制” 探索:论文提出,把对话历史等老内容渲染成图片再压缩,可以实现“信息逐渐模糊” 的生物式遗忘机制,既节省资源,又符合人类记忆规律。



在公开的评测中,DeepSeek-OCR 在文本还原准确率和效率上都超过了绝大多数同类模型,特别是在极少 Token 情况下的表现尤为突出。虽然目前主要用于 OCR 场景,但这种 “视觉压缩文本” 的思路,给未来大模型如何处理超长上下文带来了很多想象空间。无论是做大模型的上下文压缩,还是为各类智能体生成高效训练数据,这条路都很值得继续探索。
项目地址:github.com/deepseek-ai/DeepSeek-OCR
论文地址:github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
评论(0)