95%准确率:重新定义企业知识检索标准
Captain 团队正式发布了一款突破性的知识检索引擎,其基准测试准确率高达 95%,相比传统 RAG 方案的 78% 准确率实现了显著提升。该项目已获得 Y Combinator 的投资支持,目前正面向早期用户开放体验申请。
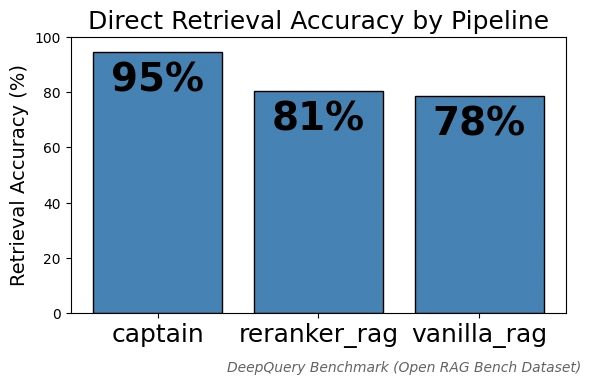
直击痛点:企业面临的检索困境
在当今企业环境中,高达 90% 的企业知识无法被传统数据库有效管理。这些海量的非结构化数据本应成为企业决策的宝贵资源,却因现有技术的局限而难以充分利用。
现有 RAG 解决方案普遍存在检索质量不稳定的问题,仅在经过预先优化的特定问题类型上才能表现良好。对于需要处理大规模文本、PDF 文档、交易日志、电子邮件、电子表格等多种数据类型的企业而言,这显然无法满足实际需求。
如果您的团队正面临以下困扰
- 缺少时间和资源进行复杂的 RAG 系统开发
- 现有搜索系统准确率不达标
- 被上下文窗口限制束缚
- 向量搜索结果不够稳定
Captain 提供了一个全新的解决思路。
技术创新:无限上下文窗口架构
Captain 的核心优势在于其独特的无限上下文窗口架构设计。团队采用了创新的分布式处理方案:将检索任务并行分配给多个大语言模型(LLM),结合嵌入技术,最终通过 Map-Reduce 机制将所有响应整合为统一输出。

这种架构设计带来了前所未有的灵活性。摆脱上下文限制后,团队得以深度优化检索引擎的准确度表现。系统可以根据实际需求动态调整 top-k 参数,甚至在需要进行完整知识审计时采用穷举式 LLM 运算。
在底层实现上,Captain 整合了业界最先进的技术栈
- 智能分块处理系统
- 多模态视觉语言模型(VLM)并行流程
- 自动化 OCR 和计算机视觉配置
- Falcon 版本自适应调整
- 推理加速硬件支持,实现超越其他前沿模型的 Token 生成速度
得益于运行在推理加速硬件之上,Captain 的搜索响应速度极快,能够在数秒内完成海量数据的检索任务。
无缝集成:适配各类数据驱动场景
Captain 的设计理念是将检索工程的复杂性完全抽象化。企业只需连接数据源,系统即可自动完成配置并提供超越传统 RAG 的准确率保障。
系统支持直接对接企业数据湖,也可通过 OpenAI 和 Versal AI 的 SDK 在数秒内完成部署。无论是处理运维日志、损益表,还是数十年积累的非结构化数据,Captain 都能提供可扩展、高速且精准的内部 AI 搜索能力。
Captain 展现出色的多模态处理能力,特别适合以下数据驱动型工作场景
- 海量文本文档和 PDF 的快速浏览
- 交易日志的深度分析
- 企业邮件的智能检索
- 电子表格数据的关联查询
- 以及更多混合数据类型的复杂场景
系统可直接部署在企业云环境中,确保数据安全的同时提供强大的检索性能。
团队背景:深耕 AI 领域的技术专家
Captain 由两位资深技术构建者联合创立,两人在数据和 AI 领域拥有深厚积累。

联合创始人 Lewis(右)此前创立的公司成功解决了代码生成中的幻觉问题,在 AI 可靠性方面积累了丰富经验。另一位联合创始人 Edgar(左)专注于自然语言处理和 AI 研究,过去 3 年持续构建生产级 RAG 管道系统。
正是这些一线实践经验,让团队深刻理解现有系统的痛点和局限。他们认为,AI 行业已经到了需要更准确替代方案的关键时刻。
市场洞察:来自行业巨头的一致反馈
今年夏天,Captain 团队与Snowflake和Databricks的众多工程师进行了深入交流。令他们印象深刻的是,几乎所有人都表达了相同的困扰
“市面上缺少真正好用的可扩展非结构化数据搜索方案。”
这一市场空白,正是 Captain 诞生的契机。
而现在,这个问题有了答案。
评论(0)