原文:Speech-to-Retrieval (S2R): A new approach to voice search
作者:Ehsan Variani 和 Michael Riley,谷歌研究院研究科学家
语音搜索现在由我们全新的语音到检索引擎提供支持,该引擎可以直接从您的语音查询中获取答案,而无需先将其转换为文本,从而为每个人提供更快、更可靠的搜索体验。
基于语音的网络搜索的演变
基于语音的网络搜索已经存在很长时间,并继续被许多人使用,其底层技术正在快速发展,以支持更多的应用场景。谷歌最初的语音搜索解决方案使用自动语音识别(ASR)将语音输入转换为文本查询,然后搜索与该文本查询匹配的文档。然而,这种级联建模方法面临的挑战是,语音识别阶段的任何细微错误都可能显著改变查询的含义,从而产生错误的结果。
例如,想象有人通过语音搜索爱德华·蒙克的著名画作《呐喊》。搜索引擎使用典型的级联建模方法,首先通过 ASR 将语音查询转换为文本,然后再将文本传递给搜索系统。理想情况下,ASR 会完美地转录查询。搜索系统随后接收正确的文本 "呐喊画作" 并提供相关结果,如这幅画的历史、它的含义以及它的展出地点。然而,如果 ASR 系统将 "scream" 中的 "m" 误认为 "n" 会怎样?它会将查询误解为"screen painting"(屏幕绘画),并返回关于屏幕绘画技术的不相关结果,而不是蒙克杰作的详细信息。

[视频演示:ASR准确性对语音搜索至关重要。展示系统正确转录查询与错误转录查询时会发生什么。]
为了防止网络搜索系统中出现此类错误,如果系统能够直接从语音映射到所需的检索意图,完全绕过文本转录环节,会怎样?
语音到检索(S2R)的诞生
这就是语音到检索(S2R)的用武之地。从本质上讲,S2R 是一种直接从语音查询中解释和检索信息的技术,无需经过可能存在缺陷的中间步骤来创建完美的文本转录。它代表了机器处理人类语音方式的根本性架构和理念的转变。当今常见的语音搜索技术专注于 "说了什么词?" 这个问题,而 S2R 旨在回答一个更强大的问题:"正在寻求什么信息?" 这篇文章探讨了当前语音搜索体验中存在的巨大质量差距,并展示了 S2R 模型如何填补这一差距。此外,我们正在开源简单语音问题(SVQ)数据集,这是一个包含 17 种不同语言和 26 个地区录制的简短音频问题的集合,我们使用它来评估 S2R 的性能潜力。SVQ 数据集是新的大规模声音嵌入基准(MSEB)的一部分。
评估S2R的潜力
当传统的 ASR 系统将音频转换为单个文本字符串时,它可能会丢失有助于消除歧义的上下文线索(即信息丢失)。如果系统在早期阶段误解了音频,该错误就会传递给搜索引擎,而搜索引擎通常缺乏纠正它的能力(即错误传播)。因此,最终的搜索结果可能无法反映用户的意图。
为了研究这种关系,我们进行了一项实验,旨在模拟理想的ASR性能。我们首先收集了一组代表性的测试查询,反映典型的语音搜索流量。关键的是,这些查询随后由人工标注员手动转录,有效地创建了一个 "完美ASR" 场景,其中转录是绝对真实的。
然后,我们建立了两个不同的搜索系统进行比较(见下图):
- 级联ASR代表典型的实际设置,其中语音通过自动语音识别(ASR)系统转换为文本,然后将该文本馈送到检索系统。
- 级联真值通过将完美的真值文本直接发送到同一检索系统来模拟"完美"的级联模型。
然后,来自两个系统(级联ASR和级联真值)的检索文档与原始真实查询一起呈现给人工评估员或 "评分员"。评估员的任务是比较两个系统的搜索结果,对它们各自的质量提供主观评估。
我们使用词错误率(WER)来衡量ASR质量,使用平均倒数排名(MRR)来衡量搜索性能——这是一个统计指标,用于评估任何对一组查询样本产生可能响应列表的过程,按正确性概率排序,并计算为所有查询中第一个正确答案排名的倒数的平均值。真实世界系统和真值系统之间的MRR和WER差异揭示了 SVQ 数据集中一些最常用的语音搜索语言的潜在性能提升(如下所示)。
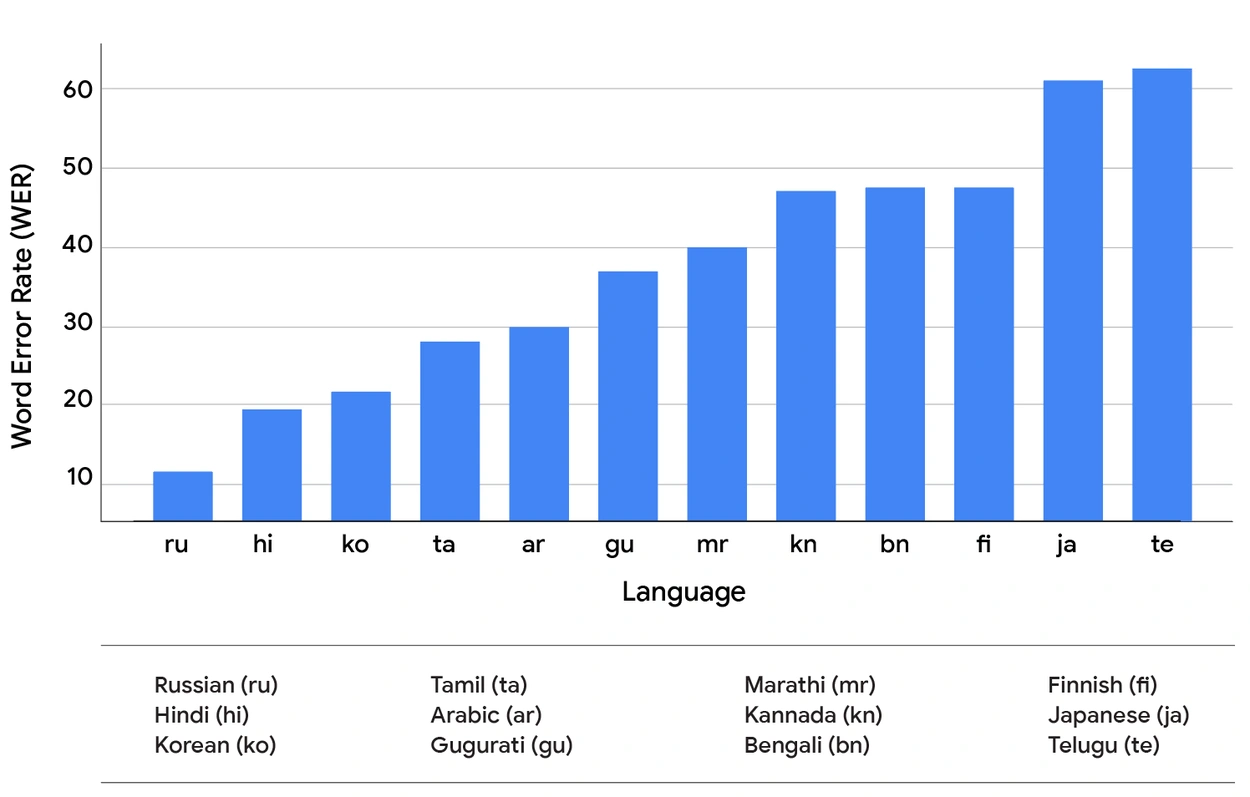
[图表1:SVQ数据集中各语音搜索语言的ASR模型词错误率(WER)。]
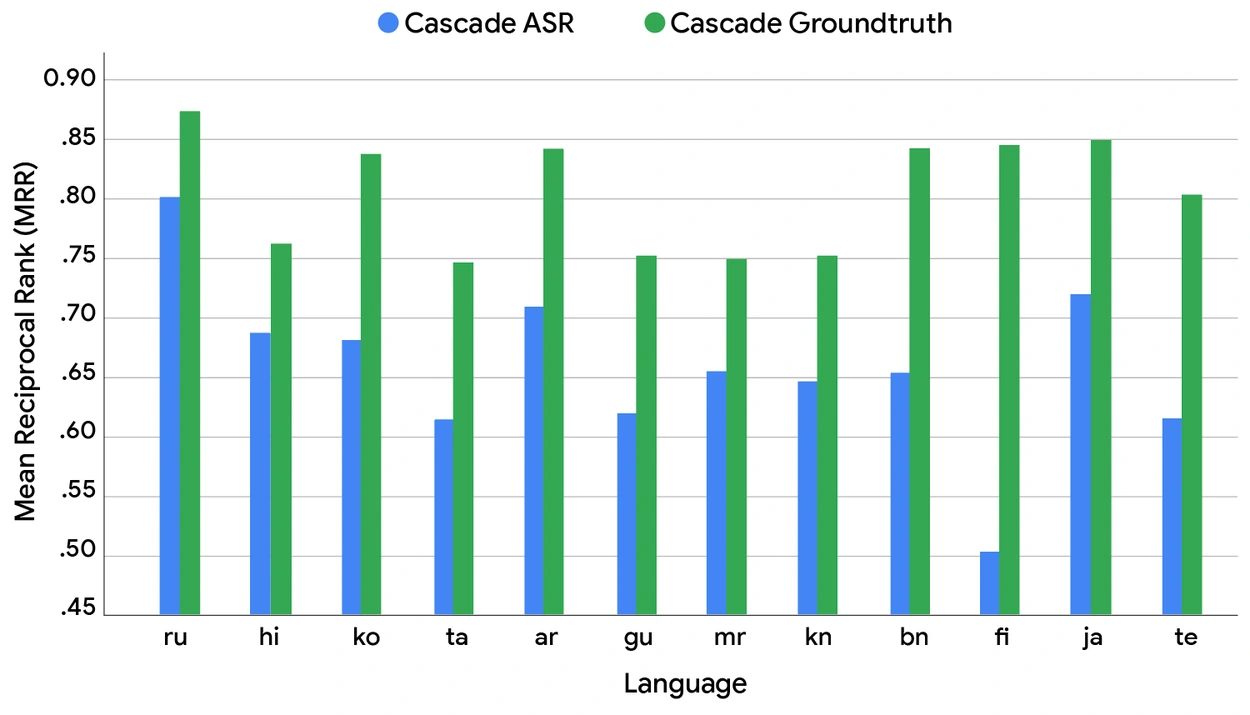
[图表2:当前真实世界("级联ASR";蓝色)模型与真值(即完美;"级联真值";绿色)的MRR对比。]
这一比较的结果得出了两个关键观察结果。首先,如上面两张图表的比较所示,我们发现较低的 WER 并不能可靠地导致不同语言之间更高的 MRR。这种关系很复杂,表明转录错误对下游任务的影响并未被 WER 指标完全捕获。错误的具体性质——而不仅仅是它的存在——似乎是一个关键的、依赖于语言的因素。其次,更重要的是,在所有测试语言中,两个系统之间存在显著的MRR差异。这揭示了当前级联设计与完美语音识别理论上可能达到的性能之间存在巨大的性能差距。这一差距代表了S2R模型从根本上改善语音搜索质量的明确潜力。
S2R 的架构:从声音到意义
我们的 S2R 模型的核心是双编码器架构。这种设计具有两个专门的神经网络,它们从大量数据中学习以理解语音和信息之间的关系。音频编码器处理查询的原始音频,将其转换为捕获其语义的丰富向量表示。同时,文档编码器为文档学习类似的向量表示。
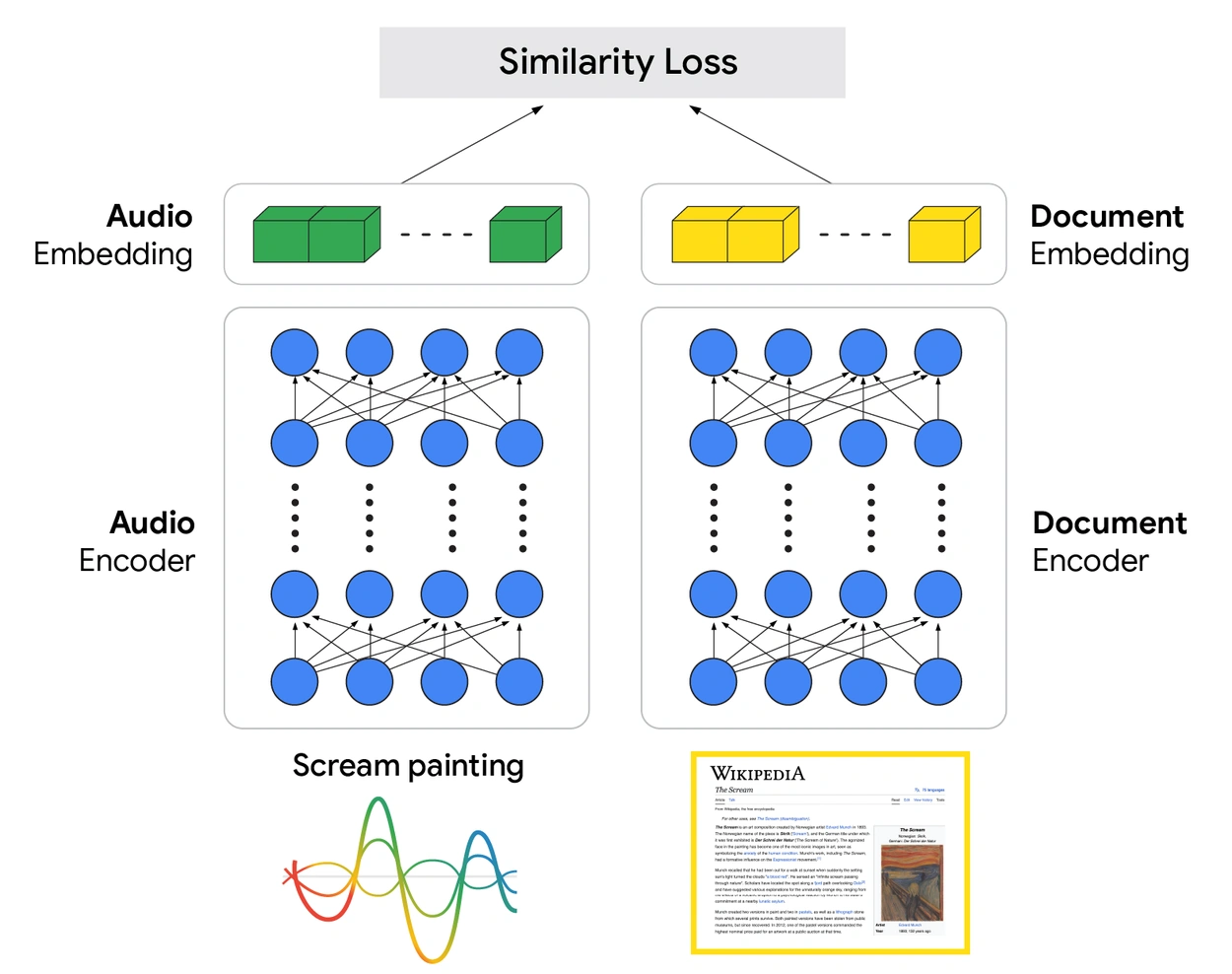
[图示:音频和文档嵌入之间相似性损失的差异。]
该模型的关键在于它的训练方式。使用大量配对的音频查询和相关文档数据集,系统学习同时调整两个编码器的参数。训练目标确保音频查询的向量在表示空间中与其对应文档的向量在几何上接近。这种架构允许模型直接从音频中学习检索所需的基本意图,绕过了转录每个单词这一脆弱的中间步骤,而这正是级联设计的主要弱点。
S2R模型的工作原理
当用户说出查询时,音频会流式传输到预训练的音频编码器,该编码器生成查询向量。然后,通过复杂的搜索排名过程,使用该向量从我们的索引中有效地识别出一组高度相关的候选结果。
[动画演示:S2R如何处理语音查询。]
上面的动画展示了 S2R 如何理解和回答语音查询。它从用户的语音请求 "呐喊画作" 开始。音频编码器将声音转换为丰富的音频嵌入,这是一个代表查询深层含义的向量。然后使用该嵌入扫描大量的文档索引,浮现出具有高相似性得分的初始候选结果,如《呐喊》的维基百科页面(0.8)和蒙克博物馆网站(0.7)。
但找到相关文档只是开始。关键的最后一步由搜索排名系统编排。这个强大的智能系统远超初始分数,将它们与数百个其他信号编织在一起,以深入理解相关性和质量。它在几分之一秒内权衡所有这些信息,编排最终排名,确保向用户呈现最有帮助和最值得信赖的信息。
评估S2R
我们在 SVQ 数据集上评估了上述S2R系统:
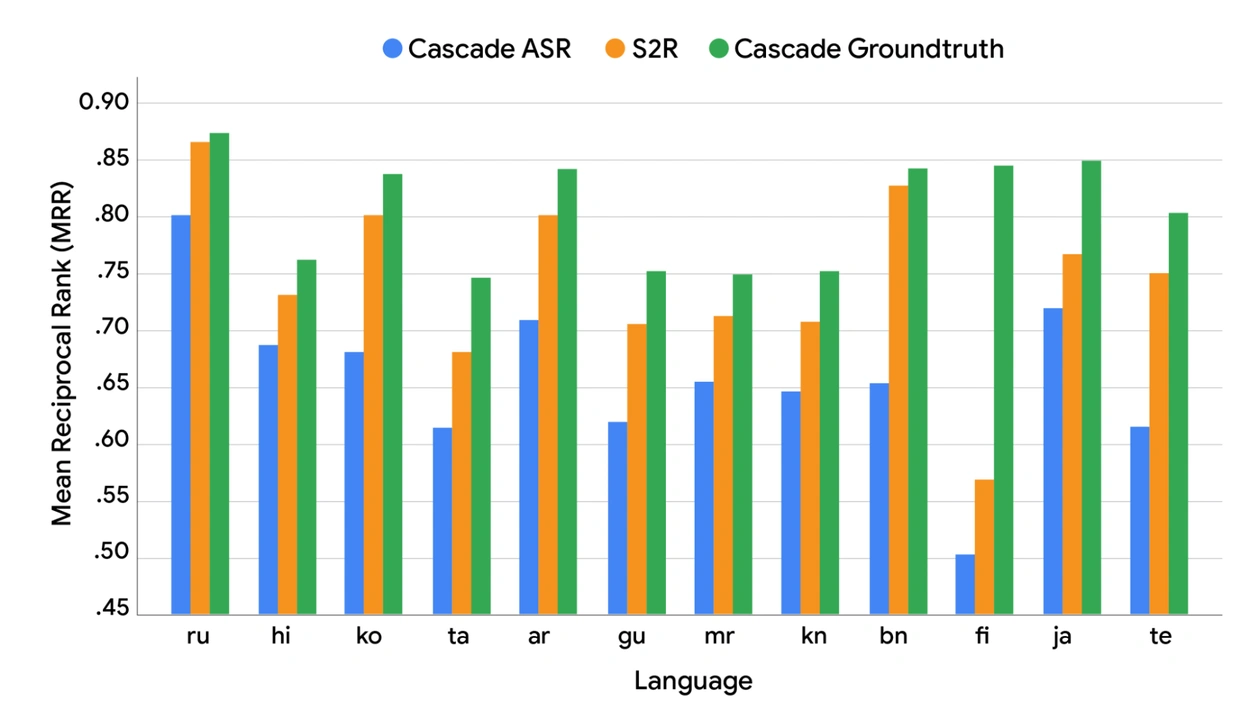
[图表3:当前真实世界("级联ASR";蓝色)模型与真值(即完美;"级联真值";绿色)以及S2R模型性能("S2R"橙色条)的MRR对比。]
S2R模型的性能(橙色条)显示了两个关键结果:
- 它显著优于基准级联 ASR 模型。
- 它的性能接近级联真值模型建立的上限。
虽然前景看好,但剩余的差距表明还需要进一步的研究。
语音搜索的新时代现已上线
转向 S2R 驱动的语音搜索不是理论演练,这是一个实时的现实。通过谷歌研究院和搜索部门之间的密切合作,这些先进的模型现在正在为多种语言的用户提供服务,在准确性方面实现了超越传统级联系统的重大飞跃。
为了帮助推动整个领域的发展,我们还将 SVQ 数据集作为大规模声音嵌入基准(MSEB)的一部分开源。我们相信共享资源和透明评估会加速进步。本着这种精神,我们邀请全球研究社区使用这些数据,在公共基准上测试新方法,并加入构建下一代真正智能语音界面的努力。
致谢
作者衷心感谢所有为这个项目做出贡献的人,他们的关键投入使其成为可能。我们特别感谢我们的同事Hawi Abraham、Cyril Allauzen、Tom Bagby、Karthik Kumar Bandi、Stefan Buettcher、Dave Dopson、Lucy Hadden、Georg Heigold、Sanjit Jhala、Shankar Kumar、Ji Ma、Eyal Mizrachi、Pandu Nayak、Pew Putthividhya、Jungshik Shin、Sundeep Tirumalareddy和Trystan Upstill。我们还要感谢那些帮助准备这篇文章的人:Mark Simborg的大量编辑工作,Kimberly Schwede的精彩插图,以及Mickey Wurts的宝贵协助。
评论(0)