Google 发布了第八代张量处理器单元 Tensor Processing Unit ,简称 TPU 。这一代产品不再用一颗芯片兼顾所有场景,而是拆成两条路线。面向大规模模型训练的 TPU 8t ,以及面向低时延推理的 TPU 8i 。 Google 给出的判断很直接, AI 正从“模型时代”走向“智能体时代”,基础设施也必须随之改写。

Google Cloud AI 与基础设施高级副总裁兼首席技术专家 Amin Vahdat 表示,这一代 TPU 是十多年研发的阶段性成果,目标是用更高效率和更大规模,支撑下一代超级计算系统。从 Gemini 这样的基础模型,到越来越复杂的智能体工作流, Google 想用 8t 和 8i 把训练、部署和推理三件事分别做到更极致。

Google 这次的核心思路,其实是承认 AI 工作负载已经明显分化。训练前沿模型,需要的是吞吐、互连带宽和集群扩展能力。智能体推理,需要的却是低时延、更高的内存带宽,以及多智能体协作时尽量少的等待。两种需求硬塞进同一块芯片里,听上去省事,实际往往两头都不够好。 Google 几年前就预判,随着前沿模型进入生产环境,推理会成为客户越来越重的负担。再加上智能体开始流行,训练和服务分开优化,已经不是锦上添花,而是现实选择。
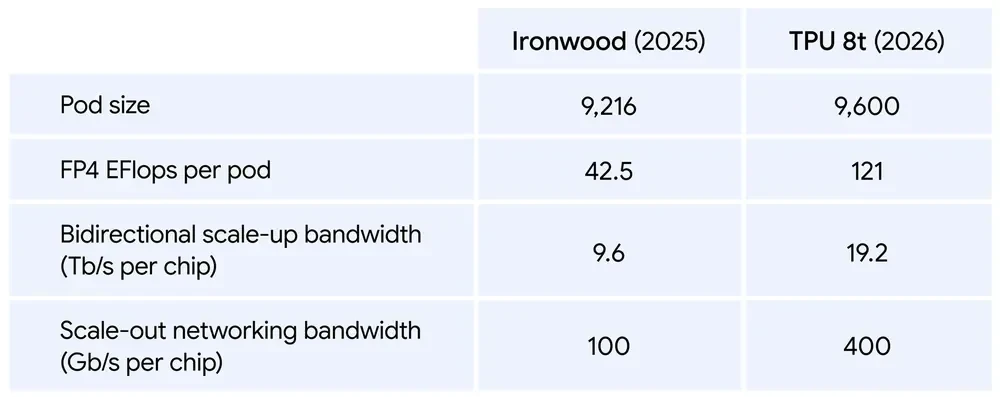
TPU 8t 被定义为训练主力。 Google 的目标很激进,要把前沿模型的开发周期从“按月算”压缩到“按周算”。这块芯片重点强化了计算吞吐、共享内存和芯片间带宽,同时继续盯住能效和有效计算时间。按 Google 的说法, TPU 8t 在单个 Pod 上的计算性能,比上一代提升接近 3 倍。
更关键的是规模。单个 TPU 8t Superpod 现在最多可以扩展到 9600 颗芯片,并配备 2PB 共享高带宽内存。芯片间带宽较上一代翻倍,整套架构可提供 121 ExaFlops 的算力。这意味着极复杂的大模型训练,能够从一个更大的统一内存池中获益,减少传统大规模训练里常见的数据搬运和切分成本。
Google 还补了一刀在利用率上。 TPU 8t 集成了快 10 倍的存储访问能力,并通过 TPUDirect 让数据直接进入 TPU ,减少中间链路损耗。配合新的 Virgo Network 、 JAX 和 Pathways 软件栈,这套系统在单一逻辑集群中最高可实现近百万颗芯片的接近线性扩展。这个数字当然更像一种上限宣示,而不是多数客户立刻会用到的现实配置,但它说明 Google 正在把 TPU 当成真正的超算平台来做,而不只是云上的 AI 加速卡。
训练系统的另一条暗线是“别掉链子”。 Google 提到, TPU 8t 的设计目标是将“有效产出时间”也就是 goodput 提高到 97% 以上。这个指标衡量的不是理论峰值,而是真正用于训练的有效时间。大规模训练最怕的不是某个部件慢一点,而是硬件故障、网络停顿、断点恢复这些细小中断层层叠加,最后把几天时间吃掉。为此, Google 在可靠性、可用性和可维护性上做了很多系统级设计,包括跨数万颗芯片的实时遥测、故障 ICI 链路的自动绕行,以及无需人工介入的光路交换重构。
如果说 TPU 8t 解决的是“怎么更快把模型训出来”,那 TPU 8i 瞄准的就是“怎么让模型更快、更省地跑起来”。 Google 把它称作智能体时代的“推理引擎”。原因不难理解。智能体不是一次性吐出答案,它往往要拆解问题、调用工具、在多个步骤中反复推理,还可能由多个专门智能体协作完成。这样的系统,一旦某个环节多等几十毫秒,整体体验就会明显变差。
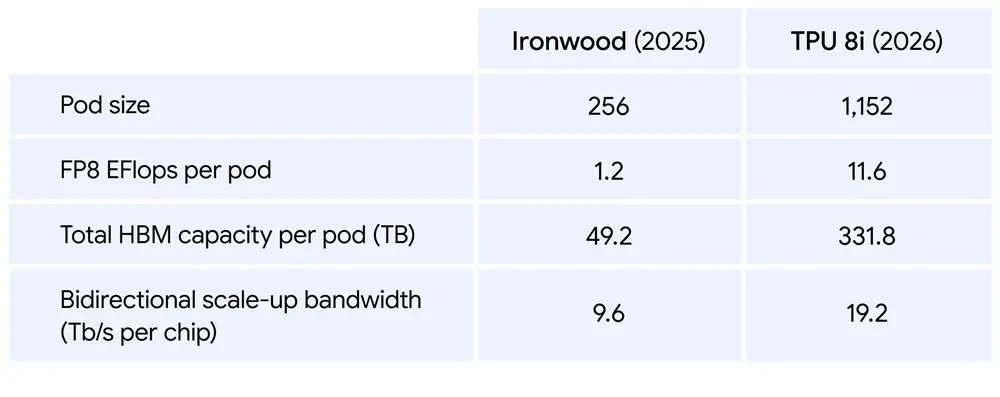
Google 为 TPU 8i 做了四项重点改造。最先是突破“内存墙”。 TPU 8i 配备 288GB 高带宽内存和 384MB 片上 SRAM ,后者比上一代增加 3 倍。这样做的目的很明确,就是尽量把模型活跃工作集留在片上,减少处理器空转等待数据。
第二项变化是主机侧。 Google 在每台服务器上把物理 CPU Host 数量翻倍,并换上自研的 Axion Arm 架构 CPU 。配合非统一内存架构 NUMA 做隔离,整个系统级性能得到了重新优化。换句话说, Google 这次不只在改加速器,也在重写 Host 到加速器之间的配合方式。
第三项针对的是混合专家模型 Mixture of Experts ,也就是 MoE 。 Google 把 ICI 互连带宽提升到 19.2Tb/s ,并引入新的 Boardfly 拓扑,将最大网络直径缩短超过 50%。这是一个很“基础设施”的改动,但影响很现实。 MoE 模型的效率,高度依赖不同专家之间的数据交换速度。网络路径一长,时延立刻放大。 Boardfly 说白了,就是在尽量让整个 Pod 像一个低时延整体那样工作。
第四项是减少全局操作的拖累。 TPU 8i 新增片上集体通信加速引擎 Collectives Acceleration Engine ,简称 CAE ,把原本影响时延的全局操作卸载出去,片上延迟最高可降低 5 倍。 Google 给出的最终结果是, TPU 8i 的单位成本性能比上一代提高 80%,在相同成本下,企业可以支撑接近两倍的客户请求量。

这代 TPU 还有一个很鲜明的特点,就是它并不是“先做芯片,再找软件适配”,而是从一开始就按 Gemini 这类推理模型的需求反推硬件参数。 Google 说得很明白。 Boardfly 拓扑是为当下高能力推理模型的通信需求设计的。 TPU 8i 的 SRAM 容量,是按生产规模下推理模型 KV Cache 的占用来定的。 Virgo Network 的带宽目标,则来自万亿参数训练时的并行需求。这种软硬协同设计,过去是 Google TPU 的优势,这一代把这种思路推得更彻底了。
开放性上, Google 也尽量避免把 TPU 变成“只能跑自家栈”的封闭平台。 TPU 8t 和 8i 都原生支持 JAX 、 MaxText 、 PyTorch 、 SGLang 和 vLLM ,还提供裸金属访问,客户可以直接接触硬件,而不是通过虚拟化层间接调用。 Google 也提到了一些开源投入,包括 MaxText 参考实现,以及用于强化学习支持的 Tunix 。这些动作很有针对性。因为现在客户买的不只是芯片性能,还要看迁移成本和生态摩擦。
Google 反复强调的另一件事是电力。如今数据中心的约束,已经不只是“有没有足够多的芯片”,而是“有没有足够多的电”。 TPU 8t 和 TPU 8i 在性能功耗比上,相比上一代 Ironwood 最高可提升 2 倍。 Google 的做法并不局限在芯片本身,还包括把网络连接与计算集成在同一芯片上,降低 Pod 内数据搬运的功耗。数据中心层面, Google 过去五年已经把单位电力可提供的计算能力提升了 6 倍。
两款新 TPU 都采用 Google 第四代液冷技术。这个点没那么性感,却很关键。空气冷却在高密度 AI 集群面前越来越吃力,而液冷是继续提高功率密度、维持稳定性能的必经之路。 Google 还强调,由于从 Axion Host 到加速器,再到数据中心基础设施,都是自家体系,系统级能效优化空间比 Host 和芯片分别设计的大得多。

从产品定位看, Google 这次不是单纯发布两块新芯片,而是在给 AI Hypercomputer 这套大系统补齐下一阶段的核心部件。 Google 想卖的,是一整套统一堆栈,包括定制硬件、开放软件框架,以及编排、集群管理和交付模式。 TPU 8t 和 TPU 8i 都将在今年晚些时候正式开放商用,客户现在已经可以申请获取更多信息。
Citadel Securities 这样的客户已经被 Google 拿来做样板,说明 TPU 正在从“Google 自用很强”这件事,继续往“企业愿意大规模采购”推进。真正的竞争对手显然还是 NVIDIA ,只不过打法不同。 NVIDIA 仍在用更统一的平台吃下训练和推理。 Google 则押注分化,认为智能体时代的工作负载已经复杂到必须专门造两种芯片。这个判断是否完全成立,还要看客户是否愿意接受更细分的基础设施组合。但从技术路线看, Google 这次确实没有保守。