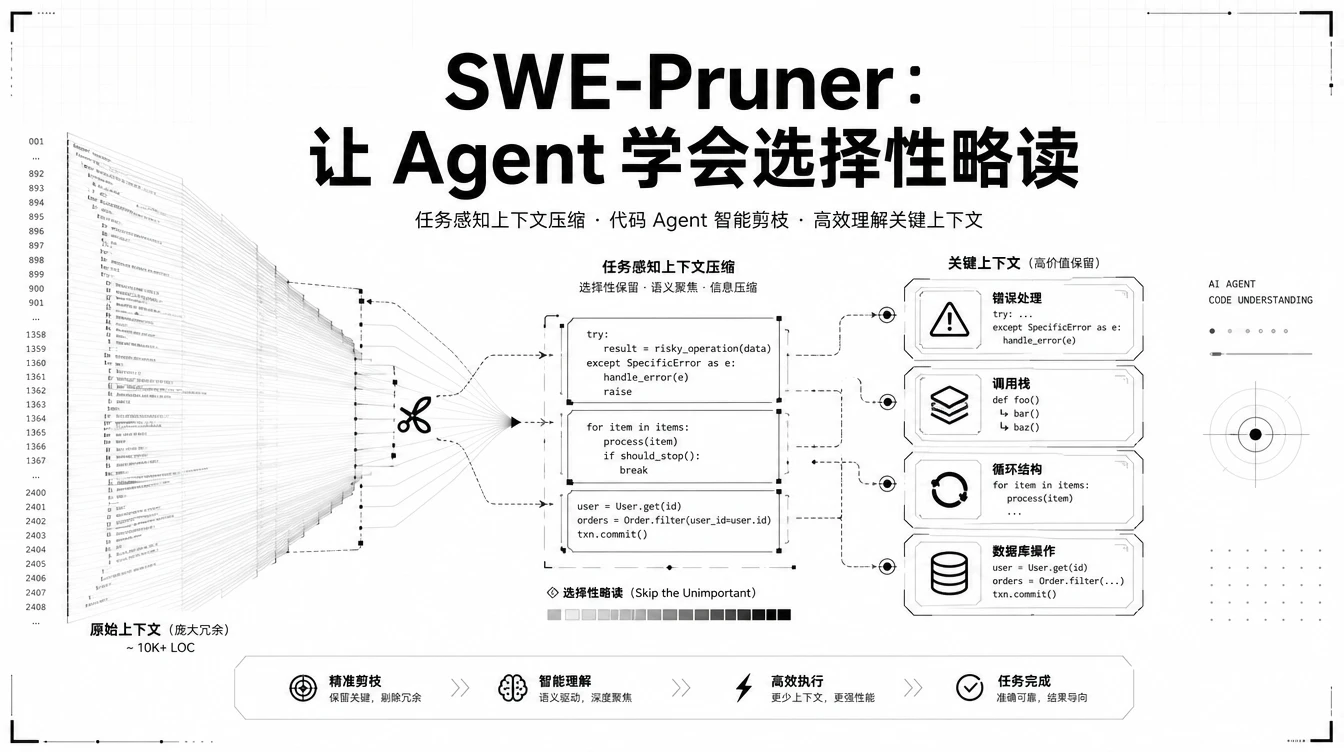
如今的代码 Agent 动不动就啃几万 Token 的上下文,既贵又慢还容易迷失。SWE-Pruner 认为,不如学学人类程序员“选择性略读”的方式。
怎么做的
论文来自arXiv(2601.16746v2),团队基于一个观察:人类调试代码时不会逐行阅读,而是带着任务目标去“扫”相关部分。比如修 bug 时只看错误处理和调用栈,找性能瓶颈时只看循环和数据库操作。
SWE-Pruner干了三件事
Agent 给自己定一个明确目标,比如“聚焦错误处理”或“关注并发逻辑”,这个目标会变成剪枝的提示。
训练了一个 0.6 B 的小模型(叫skimmer)来学习如何根据目标选择上下文。
在四个基准上测试,发现效果不错。在 SWE-Bench Verified 这类 Agent 任务上,Token 减少了 23% 到 54%,成功率反而还提升了。在单轮的长代码问答任务上,最高能压缩 14.84 倍。
为什么值得关注
之前业界做上下文压缩,主要靠困惑度(PPL)这类固定指标,问题是代码有结构,你不能把一个函数切成两半,或者漏掉一个关键的变量声明。PPL导向的压缩会破坏语法和逻辑结构,导致模型理解出错。
SWE-Pruner 的不同在于它是任务感知的。压缩什么、保留什么,是跟着当前任务目标走的。一个需要修 bug 的 Agent 和一个需要写测试的 Agent,会看到不同的上下文。
实用价值在哪儿
对于做 Agent 落地的人来说,这个思路意味着,与其抱怨模型上下文太短,不如让模型学会“看什么像什么”。
具体可以参考的方向有3个:
给 Agent设计 “目标设定”环节。在执行任务前让模型自己说“这次我关注什么”,这个信号可以被上游的压缩模块用到。
在代码检索场景里,把任务描述作为相关性判断的依据,而不是只靠语义相似度。
关注这个 0.6B 的小模型,小到可以本地跑,但能跟大模型配合,在一些边缘部署场景可能有用。
论文链接:https://arxiv.org/abs/2601.16746 Github:https://github.com/Ayanami1314/swe-pruner