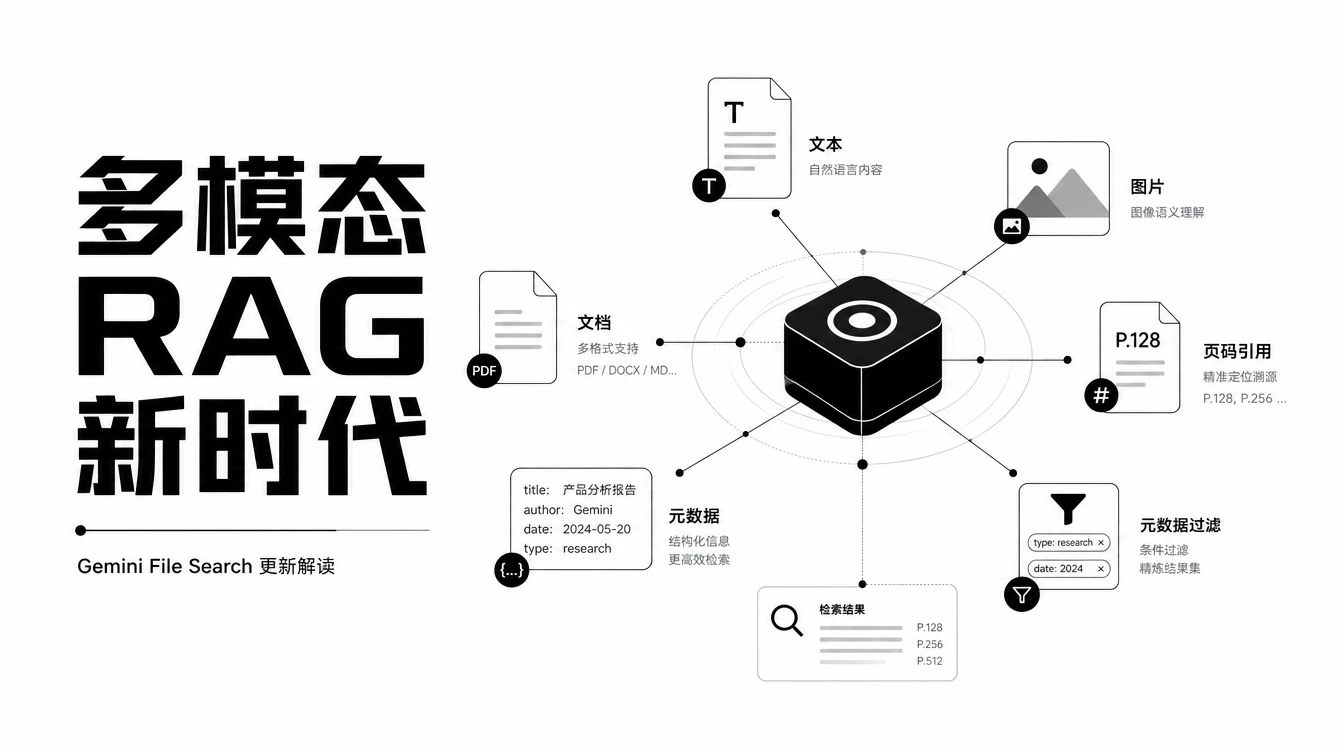
5 月 5 日,Google 给 Gemini API 的 File Search 工具加了三个功能:多模态检索、元数据过滤、页码引用。表面看是常规更新,但对做 RAG 应用的开发者来说,这可能是今年最值得动手试的一次迭代。
为什么说多模态 RAG 之前是半成品
过去两年,RAG 系统基本只处理文本。你想搜图片?先用 OCR 把图里的字扒出来,再扔进向量库。图表里的趋势线、产品照片里的设计细节、流程图里的逻辑关系,这些视觉信息 OCR 完全抓不到。
举个例子:你有一个产品目录,里面是 500 张球鞋图片,每张配了简短描述。用户问 "哪些球鞋有红色款",传统 RAG 只能匹配描述文字里带 "红" 字的条目。如果描述里写的是 "绯红" "勃艮第" 或者干脆没提颜色,就搜不到。但图片里明明有红色球鞋。
Gemini Embedding 2 换了一种做法:直接对图片本身做嵌入,把视觉语义编码进同一个向量空间。你用自然语言描述 "红色的运动鞋",它能找到图片中确实有红色元素的球鞋,不需要图片的文字标注里出现"红"这个字。这才是多模态检索该有的样子。
三个新功能拆解
第一个是多模态支持。创建 File Search Store 时指定 embedding_model 为 gemini-embedding-2,就能同时索引文档和图片。上传产品图、设计稿、数据图表,直接用自然语言查询。底层是 Gemini Embedding 2 在工作,这是 Google 第一个原生多模态嵌入模型,能把文本、图片、视频、音频映射到同一个 3072 维向量空间。根据 Google 公布的 benchmark,文本到图片的检索召回率(TextCaps recall@1)达到 89.6%,文档检索(ViDoRe v2 ndcg@10)64.9%,都超过 Amazon Nova 2 和 Voyage Multimodal 3.5。
第二个是自定义元数据过滤。用键值对给文件打标签:"部门: 法务"、"状态: 终版"、"项目: Q2财报"。搜索时带上过滤条件,把结果集缩到最相关的那几份文件。文件一多,没有过滤就是大海捞针,有过滤才是精准检索。这个功能在传统向量数据库里早就有了,Pinecone 和 Weaviate 都支持,但 Gemini File Search 是托管服务里直接集成了。
第三个是页码引用和图片溯源。模型回答问题时,每一条结论都标注出处:来自哪份文件、第几页。还会给图片的 media_id,可以下载原始图片核实。法律审查、研究报告、合规检查这些需要逐条溯源的场景,这个功能是刚需。
和自建 RAG 管线比,到底省了多少
自己搭一套多模态 RAG 管线要什么?文本嵌入模型、图像嵌入模型、向量数据库、分块策略、检索排序、重排序器、至少两个 API 端点。维护成本不算,光初始化就要写几百行代码。
Gemini File Search 的方案是:上传文件,调一个 API,剩下的全交给 Google。分块、嵌入、索引、检索全部托管。存储和查询时的嵌入免费,只收初始索引嵌入费和 Gemini 输入输出 Token 费。
但省事不等于完美。三个需要注意的点:
第一,嵌入模型一旦选定不能改。创建 Store 时选了 gemini-embedding-001(纯文本,更便宜)就不能再升级到 gemini-embedding-2(多模态)。得重新建 Store 重新索引。所以在选择前要想清楚你的数据里有多少非文本内容。
第二,目前不支持音频和视频格式。图片和 PDF 里的图可以搜,但视频文件不行。
第三,托管服务意味着数据过 Google 的服务器。对数据合规要求严格的团队(金融、医疗、政务),需要走 Vertex AI 企业通道,审计和加密能力更完整。
实操建议:三步上手
第一步,装最新 SDK:pip install -U google-genai。
第二步,创建多模态 Store:file_search_stores.create 时指定 embedding_model 为 models/gemini-embedding-2。
第三步,上传文件并查询。PDF 和图片都能直接 upload_to_file_search_store,然后在 generate_content 里传入 file_search 工具。返回结果自动带溯源信息和页码。
Seth Georgion 进行了实测:他们用传统大文本嵌入(3072 维)做向量检索时,结果经常被噪声淹没。换成 Gemini Embedding 2 后,文本到视频的 Recall@1 提升到 85.3%。这组数据来自一个真实的大型媒体公司,比 benchmark 更有参考价值。
法律科技公司 Everlaw 的 CTO Max Christoff 也提到,Gemini Embedding 2 在法律场景中提升了百万级记录的精确率和召回率,同时解锁了图片和视频的新搜索能力。法律场景对准确性的要求极高,这个评价有分量。
多模态 RAG 的战争才刚开始
Google 这次的布局很清晰:用 Embedding 2 把多模态检索做进托管服务,降低门槛的同时锁定生态。竞争对手方面,Amazon 有 Nova 2 Multimodal Embeddings,Voyage 有 Multimodal 3.5,OpenAI 的 embedding 目前还是纯文本。
对开发者来说,选择取决于你的场景:如果数据以文本为主,gemini-embedding-001 更便宜。如果有大量图片、图表、设计稿需要语义检索,gemini-embedding-2 是目前托管方案里最完整的选择。自建管线灵活但维护成本高,托管服务省事但受限于平台能力边界。


