
实测 Gemini 3 Pro Preview 构建 3D 版赛博城
实测 Gemini 3 Pro Preview 在 Google AI Studio 中,10 分钟内经 4 轮自动修正,生成可运行的 React + three.js 代码,实现百栋霓虹建筑、体积雾、动态光源与昼夜/暴雨三模式切换;结构清晰、注释完整,稳定性与响应速度较 2.5 版略有提升。

Gemini 3 全面测评
Gemini 3在数学推理、知识检索与多模态理解(图/视频)上表现顶尖,支持一键生成网站、测验、播客及自然图片编辑,研究与原型开发效率极高;但交互“情商”弱于GPT-5.1,编程生态不如Claude Sonnet 4.5成熟,API成本较高。

Grok 4.1 到底好不好用
Grok 4.1在LMArena登顶,但实测优势集中在实时抓取X平台最新推文,适合舆情分析与事件追踪;响应慢、编程能力弱、创意输出生硬是明显短板。API成本低、上手易,通用任务仍推荐ChatGPT 5.1等更成熟模型。

Google 搜索接入 Gemini 3 推出生成式 UI 功能
Google 将 Gemini 3 模型接入搜索 AI 模式,显著提升复杂问题理解与推理能力,并推出生成式 UI:支持动态视觉布局、实时生成交互工具(如三体模拟、贷款计算器)及多模态响应。目前面向美国 AI Pro/Ultra 用户开放,后续将逐步扩展。

Google 发布 Antigravity:开启 AI 辅助软件开发新纪元
Google 推出智能体开发平台 Antigravity,基于 Gemini 3 等大模型,首创“管理器+编辑器”双模界面:管理器支持异步多工作区自主执行端到端任务,编辑器提供类 IDE 的实时协作体验;强调任务级可视化验证、跨成果评论反馈与知识库驱动的自我改进。现开放免费预览版。
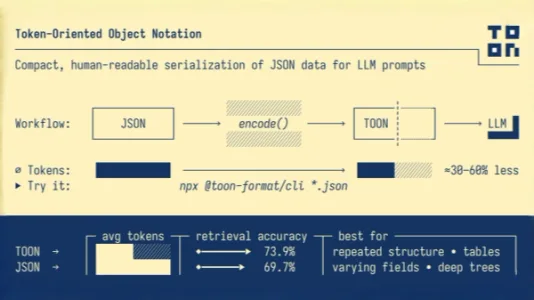
专为 AI 打造的数据格式 TOON
TOON 是一种专为大模型优化的数据格式,用缩进和表头式结构替代 JSON 的冗余符号,大幅压缩 Token 消耗(较 JSON 减少30–60%)。在209个数据检索任务中平均准确率超越 JSON,尤其适合员工名单、商品列表等规整表格数据,已提供 TypeScript 库与命令行工具支持快速转换。

AI 工具 Specific 专为后端开发打造
Specific 是专为后端开发设计的 AI 工具,能自动生成数据库、认证、文件存储等基础设施代码,并同步产出标准化 API 文档,加速前后端协作;支持与 Claude Code、Cursor 等主流智能开发工具集成,提升后端搭建效率。

AI入门玩法 同一段提示词 4款文生视频 工具对比
用同一段提示词“一名抖音舞者在无人机上跳舞,表演翻转和技巧动作”,实测海螺2.3 preview、Sora 2、可灵2.5 master与Veo 3.1 fast四款文生视频工具——重点对比动作连贯性、细节还原度与生成速度,帮你快速摸清各模型的实用边界,新手也能看懂差异。

AI工具 Vidu Q2 实现更精准的表情和动作
Vidu Q2升级后,人物表情更细腻、动作更精准,动态表现自然逼真。聚焦差异化技术路径,在国产视频生成模型中展现出扎实的细节控制能力,为AI视频创作向大众化与专业化双轨发展提供新可能。