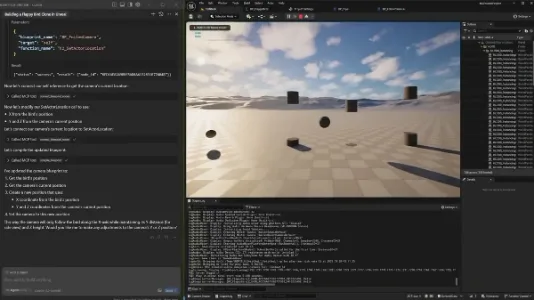
一款通过 AI 操作 Unreal 编写游戏的 MCP 插件
Chong-U Lim 开发的 Unreal MCP 插件基于 Model Context Protocol,支持通过 Cursor、Claude Desktop 等客户端用自然语言操控 Unreal Engine:从关卡搭建、蓝图创建到脚本编写均可一键生成,已实测用于快速开发 Flappy Bird 类游戏,大幅降低游戏开发门槛。

Tripo 开源两款前沿 3D 生成 AI 模型,重新定义高保真 3D 创作的未来
Tripo 开源两款高保真3D生成模型:TripoSG支持单图生成精细网格,融合校正流变换与几何监督VAE;TripoSF支持任意拓扑与1024³分辨率建模,首创SparseFlex稀疏表达,VAE模块同步开源。代码、权重、案例全部开放。
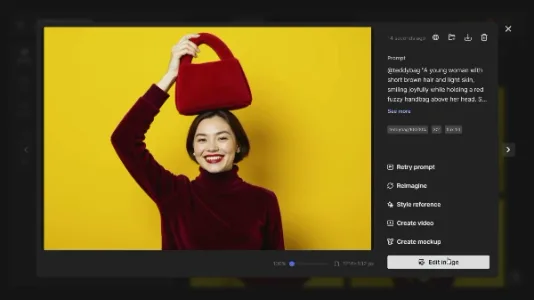
如何通过 Freepik 轻松制作产品广告视频
只需上传20张商品实拍图,Freepik即可训练专属商品模型,自动生成广告图,并通过内置编辑器优化后一键转为动态视频,全程无需专业设计或视频技能,中小商家和营销人员可快速产出高质量广告内容。
如何用 GPT-4o 制作应用界面
GPT-4o 可直接通过英文提示生成高可用应用界面,文中以音乐流媒体和数字银行为例,展示如何结合功能需求、用户画像与竞品分析,输出符合视觉规范与交互逻辑的 UI 原型,显著提升设计与开发协同效率。
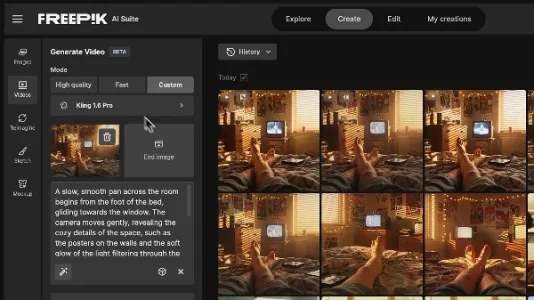
如何通过 Freepik 制作一段第一人称视角(POV)视频
Freepik 可一站式生成沉浸式第一人称视角(POV)视频。教程以90年代卧室为场景,先用AI生成高细节POV参考图,再据此生成含自然动作(如交叉双脚)与动态元素(如闪烁CRT电视画面)的视频,最后叠加“Retro TV Show”音效,快速完成怀旧风格短片。

如何通过 Freepik 制作产品展示视频
Freepik 新增 AI 视频生成功能,支持输入文字提示、上传产品图或选用平台素材,一键生成专业级产品展示视频(Mockup),大幅缩短设计与广告制作周期,让AI视频工具真正落地实用场景。

可灵推出 AI 音效功能
可灵上线AI音效功能,支持三类操作:选用预设音效、输入文字定制音效、或由系统自动分析视频内容生成匹配音效。显著提升视频制作效率与声画沉浸感,适合短视频创作者及内容生产者快速完成音效配置。
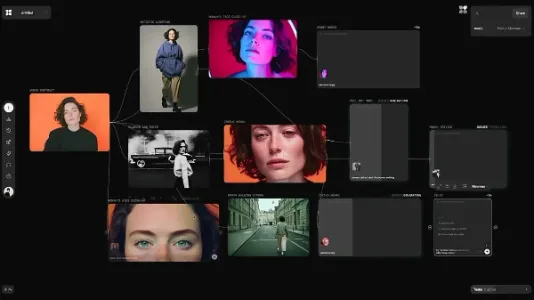
FLORA:专为创作者打造的智能画布,让创意一气呵成!
FLORA 是面向创作者的智能画布工具,整合多模态AI能力,支持从故事分析到视觉生成的一站式创意流程。内置黑白、棚拍灯光、电影感、X光、柔焦、极致细节、超写实等7种风格化选项,显著提升设计直观性与效率。
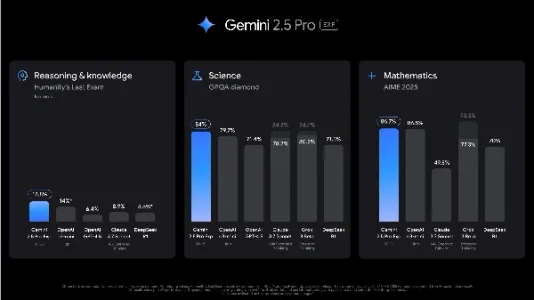
Google 推出 Gemini 2.5:最智能的 AI 模型!
Google发布Gemini 2.5,首次引入“思考能力”,可自主推理、优化决策;在GPQA、AIME 2025等高难度测试中领先,“人类终极考试”达18.8%;编程能力跃升,SWE-Bench得分63.8%,能一键生成完整p5js游戏;支持100万Token上下文与原生多模态理解。