
Freepik 推出全新背景更换功能
Freepik 新增智能背景更换功能,支持一键替换图片背景;依托 Relight 技术自动匹配主体与新背景的光影关系,显著提升合成真实感,适合设计师快速产出高质量视觉内容。

Luma 发布新一代视频生成模型 Ray2
Luma 推出新一代视频生成模型 Ray2,计算规模达 Ray1 的 10 倍,文本理解与事件逻辑建模能力显著提升,可快速生成动作连贯、细节逼真、结构合理的视频,生成成功率与实用性大幅提高,现已向所有用户开放。

海螺 AI 推出全新文生音频功能 T2A-01-HD
海螺AI上线文生音频模型T2A-01-HD,10秒即可克隆声音并保留情感细节;支持300+预设语音与17种语言及方言口音;内置情感智能系统,可自动或手动调节语气、语速、音调,并添加房间声学等专业效果,显著提升AI影片制作效率。

AI 视频人物动作精准控制工具:Kinetix
Kinetix 是一款专注动作控制的 AI 视频工具,能将上传表演视频中的人体动作精准迁移至生成角色,突破当前仅支持口型/表情同步的局限;用户只需输入场景提示词并上传动作引导视频即可使用,现开放官网等候名单注册。
实时 AI 代码审核工具:CodeRabbit
CodeRabbit 是一款实时 AI 代码审查工具,支持上下文感知的逐行建议与一键自动修复,擅长发现人工易漏缺陷;持续学习团队代码风格,官方数据显示可提升合并效率10倍、降低 bug 率50%,助力实现分钟级发布。
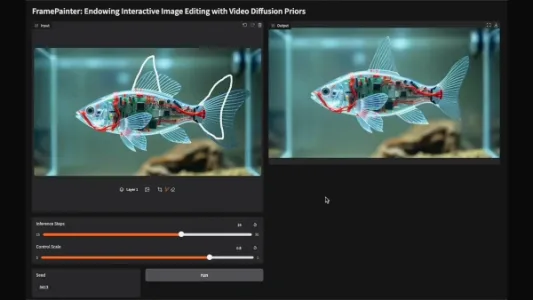
交互式图像编辑工具:FramePainter
FramePainter是一款交互式图像编辑工具,将编辑转化为“图像→视频”生成任务,降低训练成本并提升自然度;其轻量控制编码器与改进匹配注意力机制,支持精准大范围编辑,可处理倒影调整、跨物种形变等复杂场景。

超级精准的线稿上色模型:MangaNinja
MangaNinjia 是一款开源线稿上色模型,支持参考图驱动的自动上色与角色细节精准还原;独创“颜色匹配”模块可智能映射色彩关系,并提供手动微调功能;擅长跨角色上色、多参考融合等复杂场景,在颜色准确性与细节表现上优于现有工具。

LTX 推出自动音效功能
LTX 新增自动音效(Auto SFX)功能,支持在图生视频及已有视频中智能匹配并生成贴合画面的音效,无需手动添加,显著提升 AI 视频制作效率与沉浸感。

Nvidia 推出文生图模型:Sana
Nvidia 推出轻量文生图模型 Sana,支持中文提示词,最高输出 4096×4096 图像;其 0.6B 小版本仅 Flux-12B 体积的 1/20,推理速度快超 100 倍,16GB GPU 上 1 秒即可生成 1024×1024 图像,适合本地高效部署。