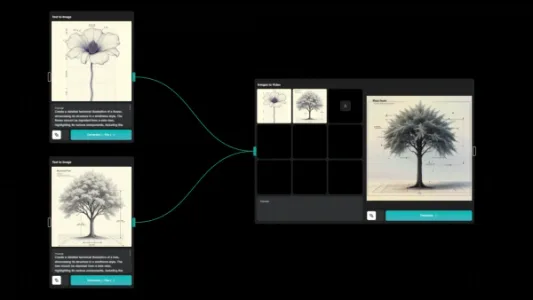
AI 视频绘画工作流工具:FLORA
FLORA 是一款模块化 AI 视频绘画工具,整合可灵、海螺AI、Runway 与 Luma,支持 Flux 和 SD 3.5 图像模型;通过类似 ComfyUI 的工作流,自由串联提示词优化、文生图、图生视频等环节;$16/月起,含 1000 张图或 50 段视频额度。
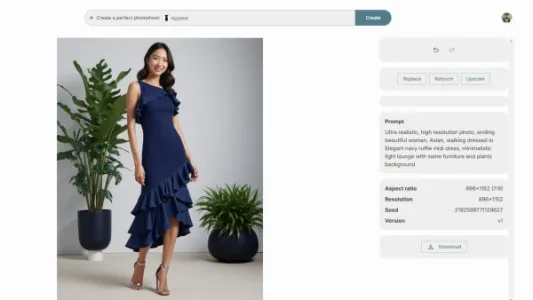
AI 电商神器 hautech.ai,轻松制作精美模特图片
hautech.ai 是一款免费 AI 工具,专为电商优化:上传服装平铺图,即可一键生成带真实感模特的穿搭图。支持自定义模特、背景及表情动作,不填则智能随机生成,三步完成,适合中小商家快速产出高质量商品图。

AutoVFX:基于自然语言指令具有物理真实感的视频特效生成框架
AutoVFX能根据单视频和自然语言指令,自动生成物理真实感的视频特效。它融合神经场景建模、大模型驱动的代码生成与物理模拟,让非专业用户也能直观、高效地完成高保真VFX编辑。
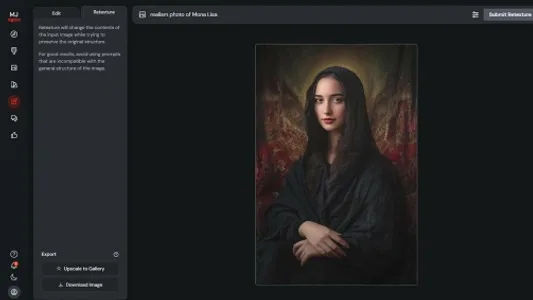
如何通过 Midjourney 纹理重绘把名画变成真实的照片
Midjourney 新增纹理重绘(Retexture)功能,上传名画图片后,输入提示词“realism photo of [名画]”,即可在保留原构图与结构的基础上,智能替换纹理与风格,生成高保真写实照片。操作简单,适合想快速将艺术作品转化为摄影风格的用户。
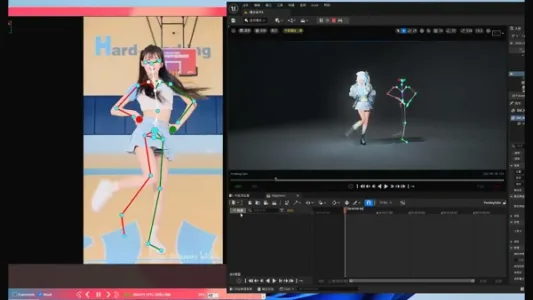
AI 动作捕捉工具:青色木偶
青色木偶是国产AI动作捕捉工具,支持用本地显卡将普通视频一键转为3D动画,无需穿戴设备或复杂校准。操作简单,适合个人创作者和小型团队快速上手,官方正在推进免费版本开发。

文字转 3D 模型 3DTopia,能够在 5 分钟内生成高质量 3D 物体
上海人工智能实验室推出3DTopia,支持文生3D,5分钟内生成高质量物体模型。采用两阶段扩散架构:先基于3D数据生成几何粗模,再用2D图像扩散模型优化纹理与细节。依托自建清洗标注的大规模开源3D数据集,融合视觉语言与大语言模型能力,模型与代码已开源。
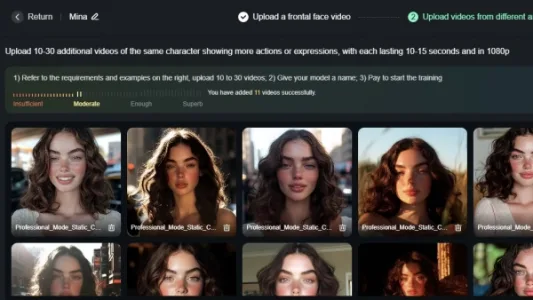
可灵自定义视频模型介绍
可灵开放自定义视频角色功能:用户上传10–30段同一人物、每段≥10秒的视频(支持真实拍摄或Midjourney生成图转视频),即可训练出高一致性AI角色模型。训练后,在文生视频提示词中调用角色名,即可精准复现其外貌、神态与动作,显著提升角色连续性与表现力。
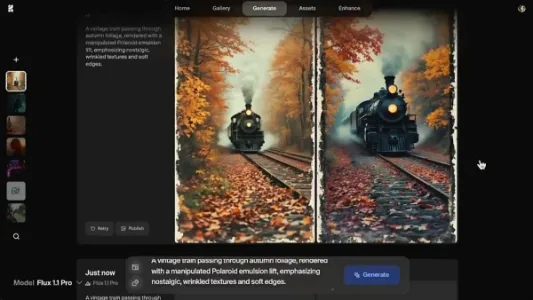
Krea.ai 一站式 AI 绘画、视频制作工具
Krea.ai 整合 Flux、Ideogram、可灵、海螺 AI、Runway 和 Luma 等主流模型,支持一键绘图与视频生成,功能全面且成本可控,适合需要多工具协同又注重性价比的创作者。

AI 绘画神器:Blendbox,精准控制画面中的多个元素
Blendbox 解决 AI 绘画中多元素精准控制的难题:先独立生成各元素,再由用户自由调整位置与大小,最后智能融合成图。流程兼顾可控性与画面质量,大幅提升复杂构图的创作效率与准确性。