#视频生成
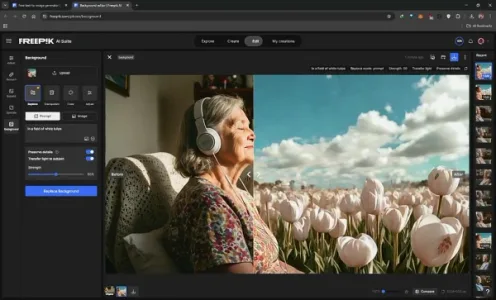
AI 创意视频:花田的魔法之旅
AI创意达人Travis Davids用Freepik智能背景替换(精准光线匹配+细节保留)与Pika首尾帧视频生成技术,将室内实景“魔法转场”为花田——白色郁金香破土生长、云彩缓缓舒展,全程自然流畅,无需复杂剪辑。

AI 是否会让我们将成为历史上最后一代读写的人类?
Victor Riparbelli 提出激进预测:AI驱动的视频与语音交互或削弱文字核心地位,孙辈或成最后一代普遍掌握读写技能的人类;译者则指出,文字在抽象表达与深度思考上不可替代,未来更可能是文字与多模态媒介共存,人类具备跨形态信息处理能力。

Pika 2.2 来了,终于支持首尾帧,可一次性生成 10 秒视频
Pika 2.2 正式上线,首次支持首尾帧控制——用户可指定起始与结束画面,精准引导视频运动和结构;单次生成时长提升至10秒,大幅增强叙事连贯性与创作自由度。

Pixverse 4.0 来了,快速添加语音、音效,一键更换视觉风格
Pixverse 4.0上线,新增语音与音效添加功能,支持一键切换视觉风格,视频生成速度与质量同步提升。虽画质未达行业顶尖,但操作友好、功能实用,持续迭代显著增强创作灵活性与沉浸感。
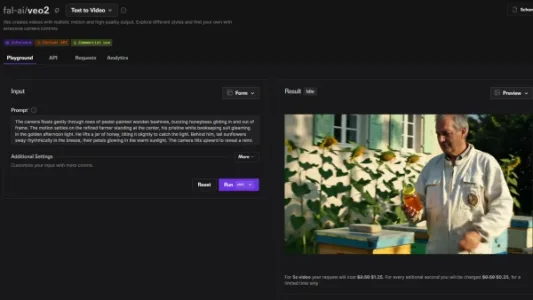
Fal.ai 正式接入 Veo 2,5 秒视频需花费 $1.25
Fal.ai 已接入 Google 最新视频模型 Veo 2,限时优惠下生成 5 秒视频仅需 $1.25;而可灵 1.6 Pro 单价低至 $0.1/秒,成本约为 Veo 2 的 40%。AI 创作者 Halim Alrasihi 已实测对比二者表现,创作者可依预算、画质与生成速度需求灵活选择。
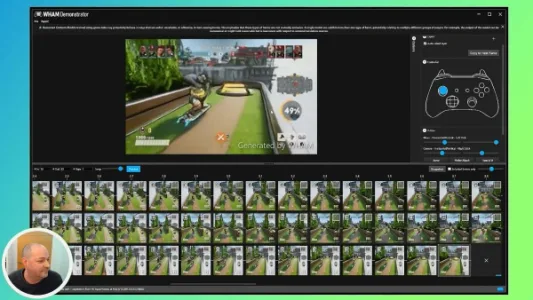
AI 让游戏成为“活生生”的世界?WAM 的无限可能!
微软WAM是一种生成式AI模型,能根据游戏画面实时预测角色动作并逐帧生成新画面,让游戏从固定脚本变为玩家可干预、可创作的动态世界。它同样有望革新影视制作与VR/AR体验,推动内容生产向“意图驱动”演进。

AI 创意视频:美食成精
AI创意达人TechHalla用Mystic v2.5 Fluid生成超写实图像,再以可灵1.6制成视频,打造“美食成精”系列:香蕉蜥蜴、爆米花猫头鹰、菠萝犰狳、可颂螃蟹等奇幻生物,在复古厨房、热带小屋、巴黎面包店等场景中,以食材质感与动物形态的精妙融合,营造好奇与诡谲交织的视觉体验。

一站式 AI 创作平台 Pollo.ai 使用教程
Pollo.ai 整合可灵、海螺、Pika、Runway、Luma 等主流 AI 视频模型,支持创作中自由切换,兼顾质量与效率。新手推荐先观看科技达人 Ben 的实操教程,快速上手核心功能与实用技巧。
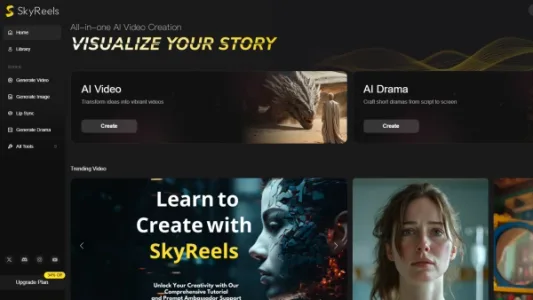
开源 AI 视频生成模型又添新成员:SkyReels-V1
SkyReels-V1 是一款专注人物表现的开源AI视频生成模型,基于腾讯HunyuanVideo深度微调,在VBench多项指标上超越主流开源模型。支持33种表情与400+自然动作,具备电影级光影构图能力,推理框架提速58.3%,普通显卡即可流畅运行。