OpenAI 在 API 平台正式发布了 GPT-5.1。这是 GPT-5 系列的最新模型,在智能与速度之间达到了平衡,专为各类智能体任务和编码工作而设计。GPT-5.1 能够根据任务复杂程度动态调整思考时间,在处理日常简单任务时速度显著提升,Token 使用效率也大幅提高。该模型还配备了 "无推理" 模式,能在无需深度思考的任务中快速响应,同时保持 GPT-5.1 的智能水平。
为了进一步提升 GPT-5.1 的效率,OpenAI 推出了扩展提示缓存功能,缓存保留时间最长可达 24 小时,能以更低成本实现后续问题的快速响应。OpenAI 的优先处理服务客户还将感受到 GPT-5.1 相比 GPT-5 更加明显的性能提升。
在编码方面,OpenAI 与 Cursor、Cognition、Augment Code、Factory 和 Warp 等初创公司展开深度合作,全面优化了 GPT-5.1 的编码风格、可控性以及代码质量。总的来说,GPT-5.1 在编码使用上更加直观易用,在任务执行过程中也能与用户进行更流畅的交互。
此外,OpenAI 还为 GPT-5.1 带来了两款全新工具:专门用于更代码编辑的 apply_patch 工具,以及能让模型执行 shell 命令的 shell 工具。
据 OpenAI 介绍,GPT-5.1 标志着 GPT-5 系列的又一次重大进步, 他们将持续投入研发更智能、更强大的模型,助力开发者构建可靠的智能体工作流程。
跨任务的高效推理
自适应推理
为了让 GPT-5.1 运行更快,OpenAI 彻底革新了模型的思考训练方式。在处理简单任务时,GPT-5.1 消耗的思考 Token 更少,带来更敏捷的产品体验和更低的 Token 成本。而面对需要深入思考的复杂任务,GPT-5.1 依然保持耐心,会探索各种方案并仔细检查成果,确保最大程度的可靠性。
Balyasny Asset Management(一家总部位于美国芝加哥的大型对冲基金公司) 表示,GPT-5.1 "在我们完整的动态评估体系中全面超越了 GPT-4.1 和 GPT-5,运行速度更是比 GPT-5 快了 2-3 倍。" 他们还指出,在需要大量使用工具的推理任务中,GPT-5.1 "在保持相似甚至更优质量的前提下,Token 使用量仅为其他主流模型的一半左右。" 同样,AI 保险公司 BPO Pace 也对该模型进行了测试,反馈称他们的智能体 "在 GPT-5.1 上的运行速度提升了 50%,准确率更是超越了 GPT-5 和其他业界领先模型。"
GPT-5.1 在简单任务上耗时更少,在复杂任务上投入更多
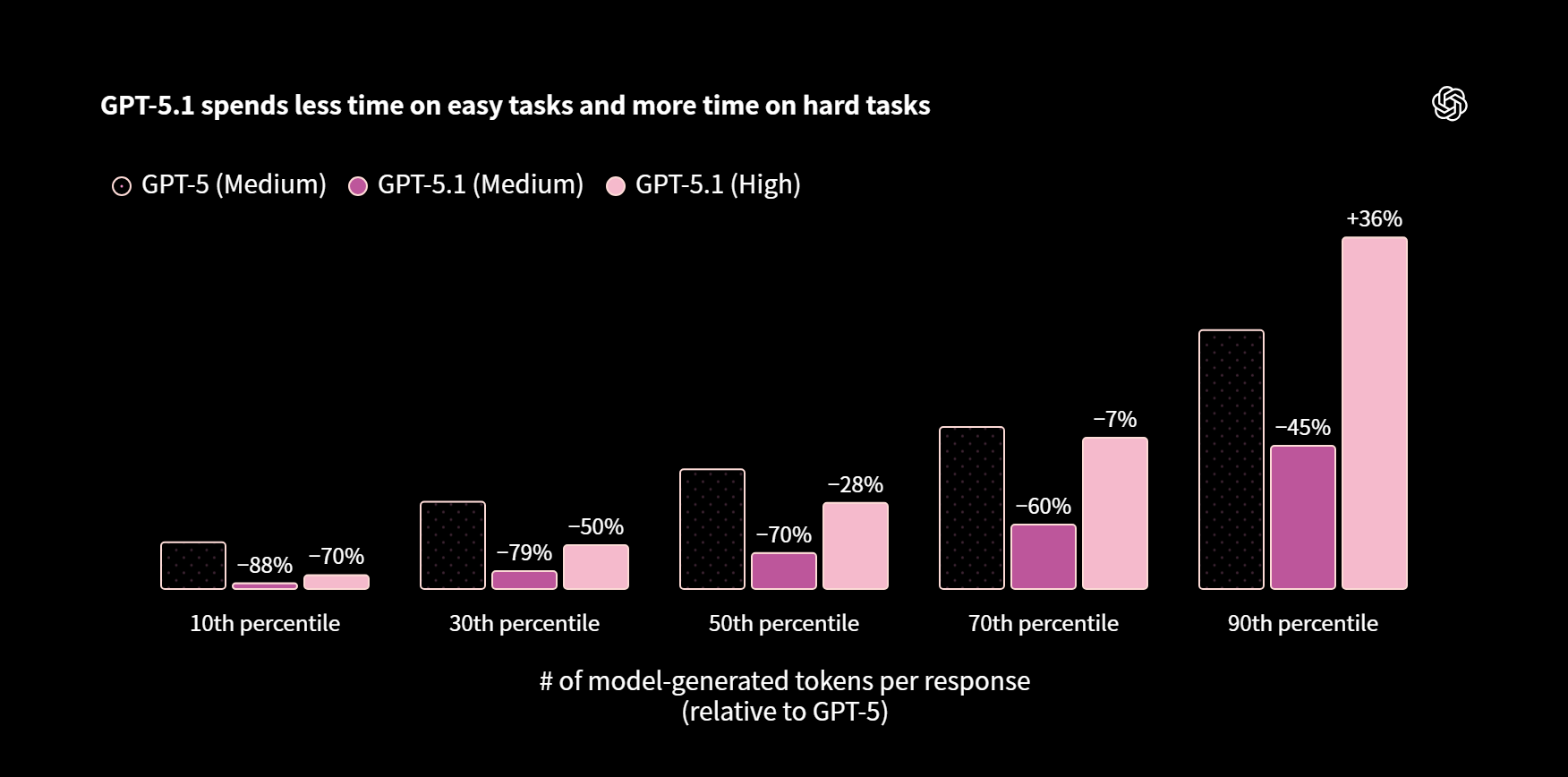
相比 GPT-5,GPT-5.1 能更灵活地动态调整思考时间。在具有代表性的 ChatGPT 任务分布中,即便在高推理强度模式下,GPT-5.1 处理简单任务的速度也快得多。
举个实际例子,当被问到 "显示一个列出全局安装软件包的 npm 命令" 时,GPT-5.1 只需 2 秒即可作答,而不是 10 秒。
GPT-5(中等)需要约 250 个 Token(约 10 秒)
显示一个列出全局安装软件包的 npm 命令
npm list -g --depth=0
GPT-5.1(中等)仅需约 50 个 Token(约 2 秒)
显示一个列出全局安装软件包的 npm 命令
你可以通过以下命令列出全局安装的 npm 软件包:
- 仅显示软件包名称:
npm ls -g --depth=0- 包含安装路径:
npm ls -g通常第一个命令就能满足你的需求。
全新"无推理"模式
开发者现在可以通过将 reasoning_effort 设为 'none' 来使用 GPT-5.1 的无推理模式。这让模型在延迟敏感场景中的表现如同非推理模型,同时保留了 GPT-5.1 的高智能水平,并额外获得了高性能工具调用能力。相比采用 "最小" 推理的 GPT-5,无推理模式的 GPT-5.1 在并行工具调用(这本身就能加快端到端任务完成速度)、编码任务、指令遵循以及搜索工具使用等方面都有更出色的表现。并且支持 OpenAI API 平台的网络搜索功能。Sierra 分享说,在他们的实际场景评估中,"无推理" 模式下的 GPT-5.1 "在低延迟工具调用性能上相比 GPT-5 最小推理模式提升了 20%"。
随着 reasoning_effort 新增 'none' 这一选项,开发者在速度、成本与智能之间的权衡上获得了更大的灵活性和控制力。GPT-5.1 默认使用 'none' 模式,这对延迟敏感型工作负载来说是理想选择。OpenAI 建议开发者在处理复杂度较高的任务时选择 'low' 或 'medium',而当智能性和可靠性比速度更重要时,则应选择 'high'。
扩展提示缓存
扩展缓存功能通过将提示在缓存中的活跃保留时间延长至 24 小时(而不是目前的几分钟),显著提升了推理效率。更长的保留时间意味着更多后续请求能够复用缓存的上下文内容。这不仅降低了延迟和成本,还为多轮对话、编码会话或知识检索等长时间运行的交互场景带来了更流畅的使用体验。
提示缓存的价格维持不变,缓存输入 Token 比未缓存 Token 便宜 90%,且缓存写入和存储不收取任何额外费用。要在 GPT-5.1 中使用扩展缓存功能,只需在 Responses 或 Chat Completions API 调用时添加 "prompt_cache_retention='24h'" 参数即可。更多详情可参阅 OpenAI 的提示缓存文档。
编码能力
GPT-5.1 在 GPT-5 已有的强大编码能力基础上更进一步,实现了更可控的编码风格、减少了过度思考、提升了代码质量、在工具调用序列中提供了更贴合用户需求的状态更新(前言),并带来了更实用的前端设计,特别是在低推理强度模式下表现尤为突出。
对于快速代码编辑这类简单编码任务,GPT-5.1 的高速响应让反复迭代变得更加轻松。值得一提的是,GPT-5.1 在简单任务上的速度优势并不会影响其处理复杂任务的能力。在 SWE-bench Verified 测试中,GPT-5.1 甚至比 GPT-5 投入了更长的思考时间,最终达到了 76.3% 的准确率。
SWE-bench Verified
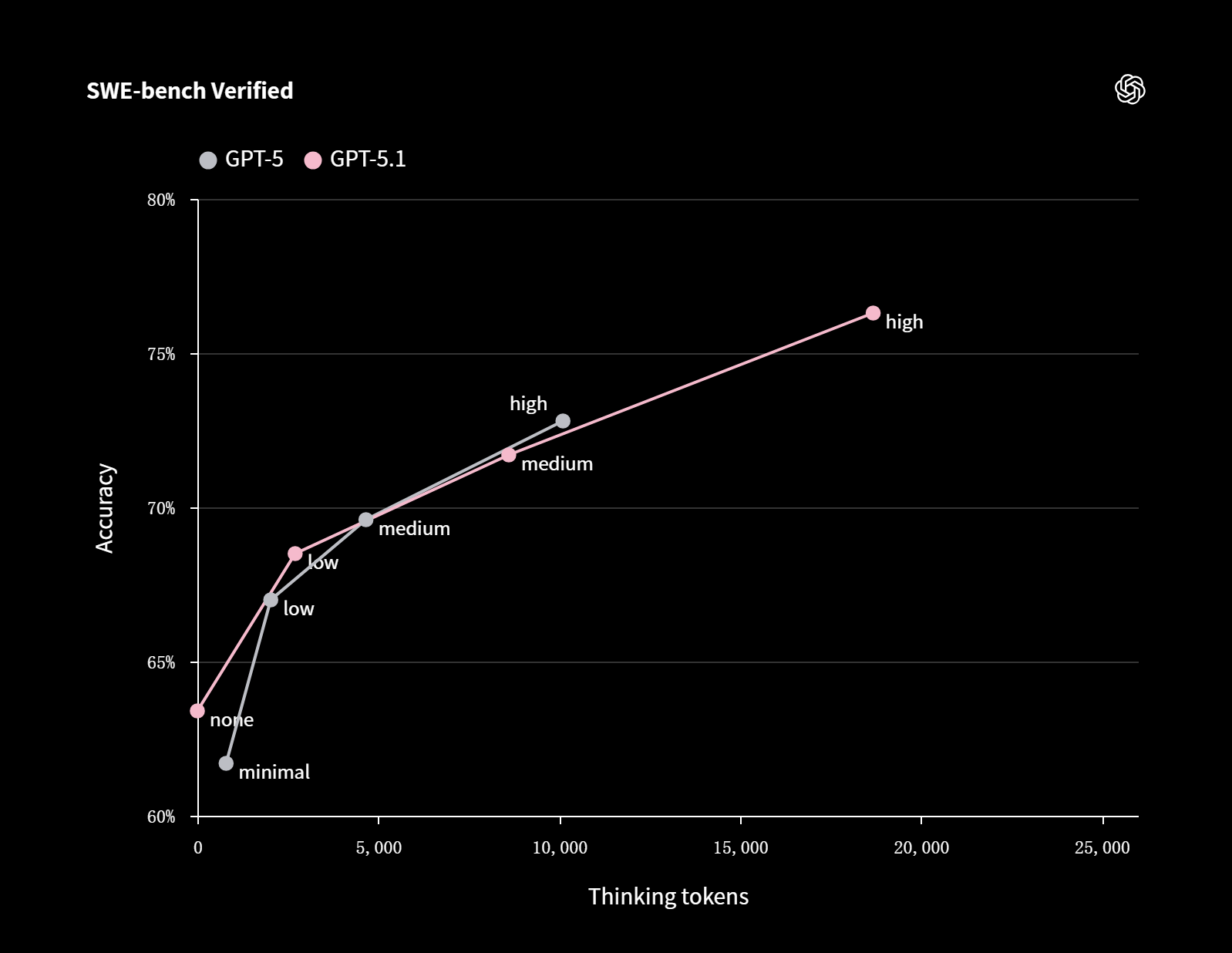
图表说明:横轴代表思考 Token 数量(0-25000 个),纵轴代表准确率(60%-80%)
- GPT-5:minimal(最小)、low(低)、medium(中)、high(高)
- GPT-5.1:none(无)、low(低)、medium(中)、high(高)
在 SWE-bench Verified 测试中,模型会获得一个代码仓库和问题描述,需要生成相应的补丁来解决问题。标签表示推理强度等级。准确率为所有 500 个问题的平均值。所有模型均使用了配备基于 JSON 的 apply_patch 工具的测试框架。
OpenAI 收集了几家编码公司对 GPT-5.1 的早期使用反馈。以下是他们的真实感受:
- Augment Code 评价 GPT-5.1 "更加深思熟虑,无效操作大幅减少,推理效率更高,任务聚焦能力更强",他们观察到 "代码修改更加精准、拉取请求更加顺畅,多文件项目的迭代速度也更快了。"
- Cline 分享说,在他们的评估中,"GPT-5.1 在我们的差异编辑基准测试中达到了业界最高水平(SOTA),提升了 7 个百分点,在复杂编码任务中展现出了卓越的可靠性。"
- CodeRabbit 将 GPT-5.1 评为 "PR 代码审查的首选模型"。
- Cognition 表示 GPT-5.1 "在理解用户需求和协同完成任务方面明显更出色。"
- Factory 表示 "GPT-5.1 响应速度明显更快,能够根据任务自适应调整推理深度,有效减少了过度思考,整体提升了开发者体验。"
- Warp 已将 GPT-5.1 设为新用户的默认模型,他们表示该模型 "在 GPT-5 系列令人瞩目的智能提升基础上又向前迈进了一大步,同时响应速度快了许多。"
"GPT 5.1 不只是又一个大语言模型,它真正具备了智能体特性,是我测试过的最自然、最自主的模型。它能像你一样思考和编码,轻松理解复杂指令,在前端开发任务中表现卓越,还能无缝融入你现有的代码库。你可以通过 Responses API 充分释放它的全部潜力,我们非常高兴能在 IDE 中提供这一能力。"
——Denis Shiryaev,JetBrains AI 开发工具生态系统负责人
GPT-5.1 的全新工具
OpenAI 为 GPT-5.1 推出了两款全新工具,帮助开发者在 Responses API 中充分发挥模型潜力。自由格式的 apply_patch 工具可以无需 JSON 转义即可更可靠地编辑代码,而 shell 工具则允许模型在用户的本地机器上执行命令。
Apply_patch 工具
自由格式的 apply_patch 工具让 GPT-5.1 能够通过结构化差异在代码库中创建、更新和删除文件。该模型不仅能提出编辑建议,还能输出补丁操作供应用程序执行并反馈结果,从而实现迭代式、多步骤的代码编辑工作流程。
要在 Responses API 中使用 apply_patch 工具,可在工具数组中添加 "tools": [{"type": "apply_patch"}],然后在输入中包含文件内容,或为模型提供文件系统交互工具。模型将生成 apply_patch_call 项,其中包含用于创建、更新或删除文件的差异信息,开发者可以在文件系统中执行这些操作。关于如何集成 apply_patch 工具的更多信息,可查阅 OpenAI 的开发者文档。
Shell 工具
shell 工具使模型能够通过受控的命令行界面与本地计算机进行交互。模型会提出 shell 命令建议,开发者的集成系统执行这些命令并返回执行结果。这形成了一个简洁的计划-执行循环,让模型能够检查系统状态、运行实用程序、收集数据,直到完成任务。
要在 Responses API 中使用 shell 工具,开发者可以在工具数组中添加 "tools": [{"type": "shell"}]。API 会生成包含待执行 shell 命令的 "shell_call" 项。开发者在本地环境中执行这些命令,然后在下一次 API 请求中通过 "shell_call_output" 项将执行结果传回。更多详情可参阅 OpenAI 的开发者文档。
定价与可用性
GPT-5.1 和 gpt-5.1-chat-latest 现已面向所有付费层级的 API 开发者开放。定价和速率限制与 GPT-5 保持一致。OpenAI 同时还在 API 中发布了 gpt-5.1-codex 和 gpt-5.1-codex-mini。虽然 GPT-5.1 在大多数编码任务中表现优异,但 gpt-5.1-codex 系列模型专门针对 Codex 或类 Codex 测试框架中的长时间运行智能体编码任务进行了优化。
开发者可以参考 OpenAI 的 GPT-5.1 开发者文档和模型提示指南开始构建应用。目前 OpenAI 没有在 API 中弃用 GPT-5 的计划,如果未来有此决定,他们会提前通知开发者。
展望未来
据 OpenAI 介绍,他们致力于迭代发布最强大、最可靠的模型,用于真实的智能体工作和编码任务。这些模型能高效思考、快速迭代,在处理复杂任务的同时让开发者保持流畅的工作状态。借助自适应推理、更强的编码性能、更清晰的用户状态更新,以及 apply_patch 和 shell 等新工具,GPT-5.1 旨在帮助开发者以更少的阻力完成构建工作。OpenAI 表示将在这一领域持续加大投入:在接下来的几周和几个月里,开发者将看到更多功能强大的智能体和编码模型问世。
附录:模型评估数据
| 评估项目 | GPT-5.1(高) | GPT-5(高) |
|---|---|---|
| SWE-bench Verified (全部 500 个问题) |
76.3% | 72.8% |
| GPQA Diamond (无工具) |
88.1% | 85.7% |
| AIME 2025 (无工具) |
94.0% | 94.6% |
| FrontierMath (带 Python 工具) |
26.7% | 26.3% |
| MMMU | 85.4% | 84.2% |
| Tau2-bench Airline | 67.0% | 62.6% |
| Tau2-bench Telecom* | 95.6% | 96.7% |
| Tau2-bench Retail | 77.9% | 81.1% |
| BrowseComp Long Context 128k | 90.0% | 90.0% |
* 针对 Tau2-bench Telecom 测试,OpenAI 为 GPT-5.1 提供了简短且通用的辅助提示以优化其表现。
评论(0)