研究团队开发出一种新方法,通过训练模型采用更简单、更可追溯的思考步骤,从而更好地理解神经网络的工作机制。
尽管神经网络为当今最强大的人工智能系统提供动力,但其工作机制仍然难以被人理解。这些模型并非通过明确的、逐步的指令编写而成,而是通过调整数十亿个内部连接(即"权重")来学习,直至精通某项任务。研究人员设计的是训练规则,而非具体的行为模式,最终形成的是一个人类难以破译的密集连接网络。
可解释性研究的新视角
随着人工智能系统能力不断增强,并对科学、教育和医疗保健等领域的决策产生实际影响,理解这些系统的工作原理变得愈发重要。可解释性研究致力于帮助人们理解模型产生特定输出的原因,而实现这一目标有多种途径。
以推理模型为例,这类模型在得出最终答案的过程中会被激励去解释其推理过程。思维链可解释性正是利用这些解释来监控模型行为。这种方法具有即时效用,目前推理模型的思维链似乎能够有效揭示欺骗等令人担忧的行为。然而,完全依赖这一特性存在脆弱性,其有效性可能随时间推移而减弱。
相比之下,机械可解释性(本研究的核心关注点)追求的是完全逆向工程模型的计算过程。虽然这种方法的即时实用性相对较低,但理论上能够提供对模型行为更为完整的解释。通过在最细粒度层面解释模型行为,机械可解释性能够减少假设前提,提供更高的可信度。不过,从低层次细节到复杂行为解释的研究路径更为漫长和艰难。
可解释性研究支撑着几个关键目标,包括实现更有效的监督机制、提供不安全或策略失调行为的早期预警信号等。该研究还与其他安全措施形成互补,如可扩展监督、对抗性训练和红队测试。
在这项研究中,研究团队展示了通过特定方式训练模型可以使其更易于解释。他们认为这项工作是对密集网络事后分析的有力补充。
这是一个极具雄心的尝试。从当前研究到完全理解最强大模型的复杂行为,仍有漫长的道路要走。尽管如此,针对简单行为的研究发现,使用该方法训练的稀疏模型包含小型、解耦的神经电路,这些神经电路既易于理解又足以执行相应行为。这表明,训练出机制可被理解的更大规模系统可能存在一条可行路径。
新方法的核心:稀疏模型学习
此前的机械可解释性研究通常从密集、纠缠的网络着手,试图将其解开。在这些网络中,每个神经元都与数千个其他神经元相连。大多数神经元似乎承担多种不同功能,这使得理解工作变得几乎不可能。
但如果训练解耦的神经网络会怎样?这种网络拥有更多神经元,但每个神经元仅有几十个连接。这样一来,生成的网络可能会更简单,也更容易理解。这正是该研究的核心假设。
基于这一理念,研究团队训练了与现有语言模型(如GPT-2)架构高度相似的语言模型,仅做了一处微小调整,强制将模型的绝大多数权重设为零。这一约束使模型只能使用神经元间极少数的可能连接。研究人员认为,这个简单的改变大幅度解耦了模型的内部计算过程。
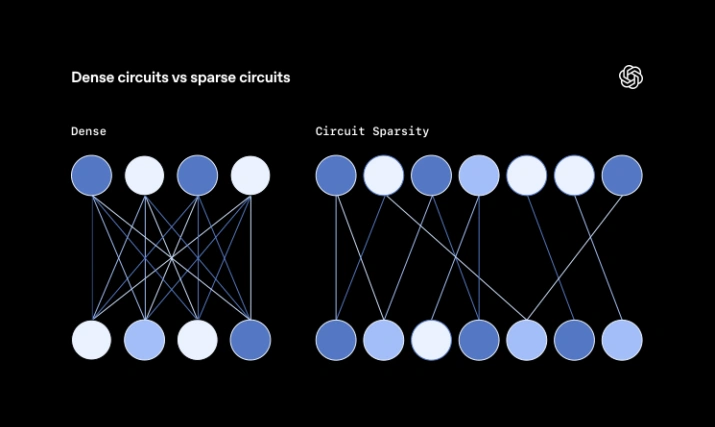
在传统的密集神经网络中,每个神经元都与下一层的所有神经元相连。而在研究团队开发的稀疏模型中,每个神经元仅与下一层的少数神经元连接。研究人员希望这能使神经元乃至整个网络更易于理解。
可解释性的评估方法
研究团队希望量化稀疏模型计算的解耦程度。他们设计了多种简单的模型行为测试,并检验能否隔离出负责每种行为的模型组件——即所谓的"神经电路"。
研究人员手工设计了一套简单的算法任务。针对每个任务,他们将模型精简至能够完成该任务的最小神经电路,并评估该神经电路的简洁程度。(详细内容参见研究论文)研究发现,通过训练更大、更稀疏的模型,可以产生能力更强、神经电路更简洁的模型。
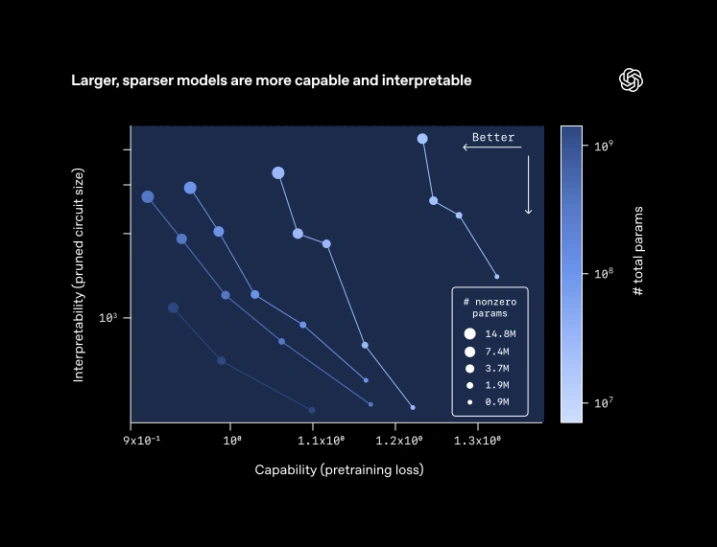
该图表展示了不同模型的可解释性与能力关系(左下角代表更优)。对于固定大小的稀疏模型,提高稀疏度(将更多权重设为零)会降低能力但提升可解释性。扩大模型规模则会向外推移这一边界,表明可以构建兼具能力和可解释性的更大模型。
以一个具体任务为例:在 Python 代码上训练的模型需要用正确类型的引号来完成字符串。在 Python 中,'hello' 必须以单引号结尾,"hello" 则必须以双引号结尾。模型可以通过记忆字符串开头的引号类型,并在结尾处复现来解决这个问题。
研究团队开发的最具可解释性的模型似乎包含了实现该算法的解耦神经电路。
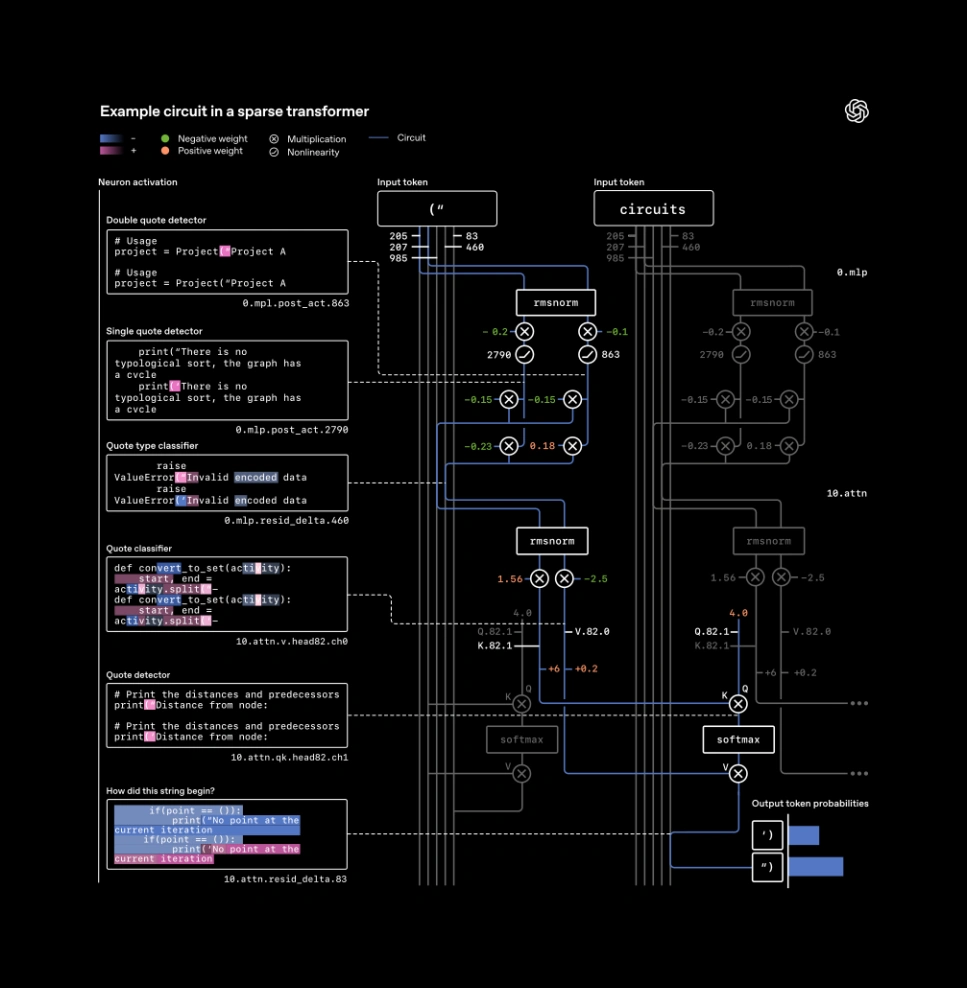
该图展示了稀疏转换器中用于预测字符串应以单引号还是双引号结尾的示例神经电路。该神经电路仅使用五个残差通道(垂直灰线)、第0层的两个 MLP 神经元,以及第 10 层的一个注意力查询-键通道和一个值通道。模型的工作流程为:(1)在一个残差通道中编码单引号,在另一个通道中编码双引号;(2)使用MLP层将其转换为一个检测任何引号的通道和一个区分单双引号的通道;(3)使用注意力操作忽略中间标记,定位前一个引号,并将其类型复制到最终标记;(4)预测匹配的结束引号。
按照研究团队的定义,上述显示的精确连接足以完成任务,即使移除模型的其余部分,这个小型神经电路仍能正常工作。这些连接同时也是必需的,删除其中任何一条边都会导致模型失效。
研究团队还探索了一些更复杂的行为。对于这些行为(例如下图所示的变量绑定),相应神经电路更难以完全解释。即便如此,研究人员仍能实现相对简洁的部分解释,这些解释能够预测模型行为。
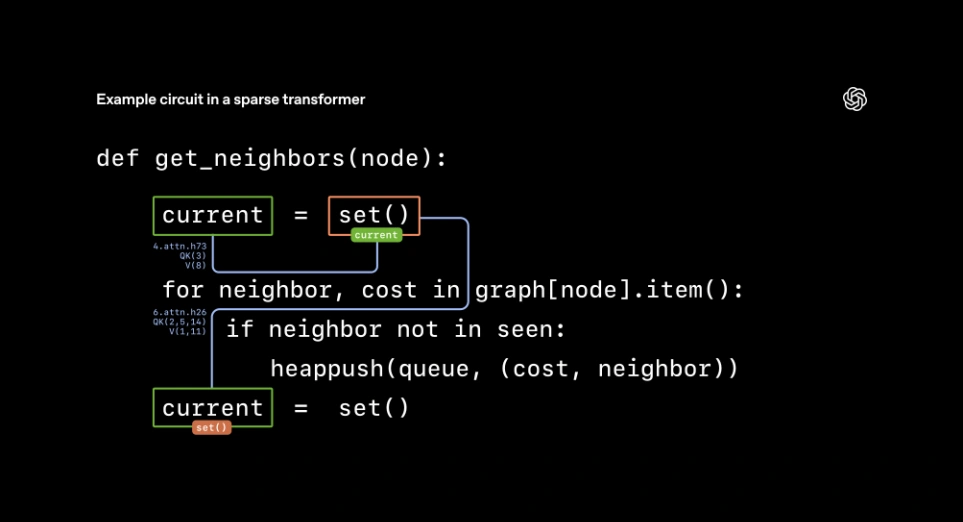
另一个示例神经电路的简化展示。为确定名为 current 的变量类型,一个注意力操作在变量定义时将变量名复制到 set() 标记中,随后另一个操作将类型从 set() 标记复制到变量的后续使用位置,使模型能够推断出正确的下一个标记。
研究的未来方向
这项工作是朝着更宏大目标迈出的初步尝试:让模型计算过程更易于理解。但前方仍有漫长的道路。目前的稀疏模型规模远小于前沿模型,其计算过程的大部分内容仍未得到解释。
接下来,研究团队希望将这些技术扩展到更大规模的模型,并解释更多的模型行为。通过列举支撑高能力稀疏模型中更复杂推理的神经电路模式,研究人员可以建立起一套理解框架,从而更有针对性地研究前沿模型。
为解决训练稀疏模型效率低下的问题,研究团队提出了两条可行路径。其一是从现有密集模型中提取稀疏神经电路,而非从零开始训练稀疏模型。从根本上说,密集模型在部署方面比稀疏模型更为高效。其二是开发更高效的可解释性模型训练技术,这类技术可能更容易应用于实际生产环境。
需要指出的是,当前研究成果并不能保证这种方法必然适用于更强大的系统,但这些早期结果令人鼓舞。研究团队的目标是逐步扩大可靠解释的模型范围,并开发相关工具,使未来的系统更易于分析、调试和评估。
评论(0)