字节跳动和浙江大学联合开发出了一款新的叫做 Loopy 的语音同步肖像模型。它的表现不亚于阿里的 EMO 和 微软的 VASA。
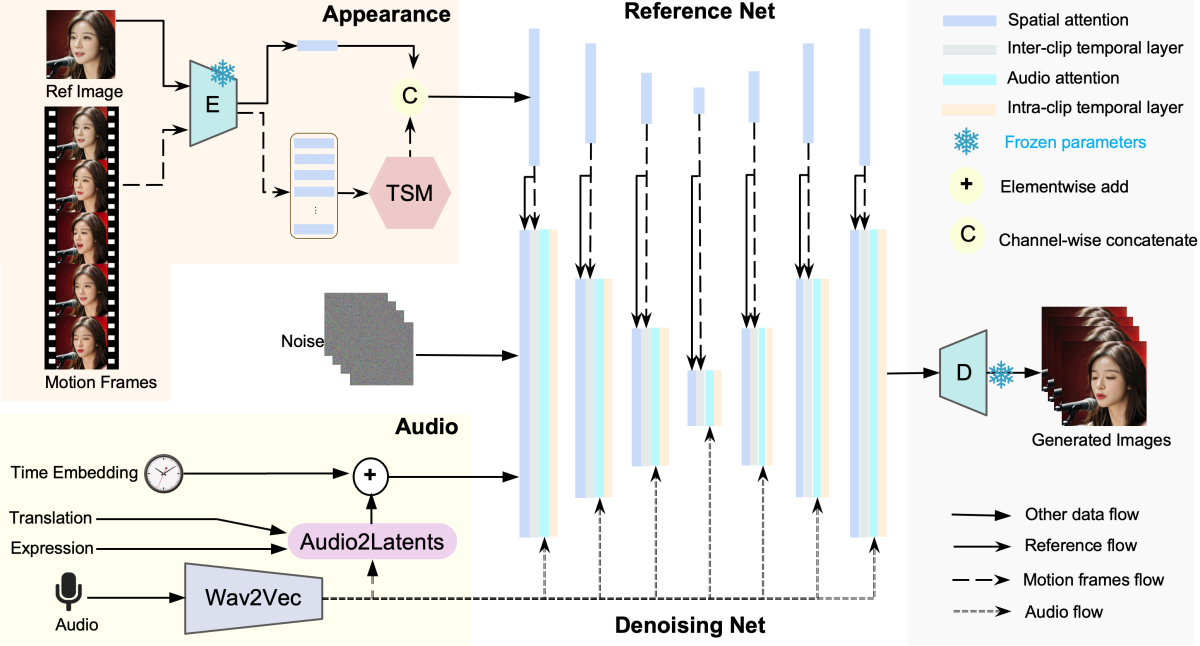
具体来讲,它拥有一个时序模块,涵盖了剪辑之间和剪辑内部的时间处理,还有一个音频到潜在特征的模块。这能让模型利用数据里的长期运动信息,从而学习自然的运动模式,并且改进音频与肖像运动的关联。这种方法去除了现有方法中在推理时需要手动指定空间运动模板来限制运动的要求,进而在各类场景中给出了更逼真、更高质量的结果。
Loopy 支持多种视觉和音频风格。仅凭一张人物肖像和一段音频,它就能生成生动的运动细节,比如非语言动作(如叹气)、情感驱动的眉毛和眼睛运动,以及自然的头部运动。
Loopy 可以根据不同的音频输入生成相应运动的结果,即使是对于同一参考图像,无论音频是快速的、舒缓的,还是歌唱表演,视频的表现都相当自然。
无论是照片、动漫形象还是雕塑,Loopy 的表现一样出色
Loopy 甚至还支持侧面的人物肖像,极大地拓展了它的应用范围
Loopy 项目地址:loopyavatar.github.io