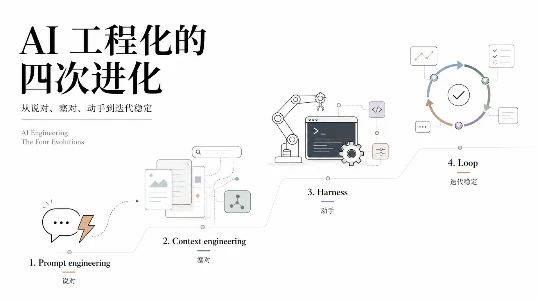
4月30日,Karpathy 在 Sequoia Ascent 2026 做了一个炉边谈话,标题叫 "Software 3.0"。这个演讲的信息密度相当高,而且说出了几句相当有冲击力的话。
他说,2025 年 12 月是一个 "Agentic 拐点"。
不是模型突然变聪明了,而是默认工作流变了。以前你写代码,是一行一行敲进去。现在你把一个完整任务丢给 Agent,它自己写、自己跑测试、自己修 bug。单位从 "代码行" 变成了 "宏观动作":“实现这个功能”、“重构这个子系统”、“研究这个库”。
这意味着什么?程序员从代码撰写者变成了 Agent 编排者。
上下文窗口就是新的程序
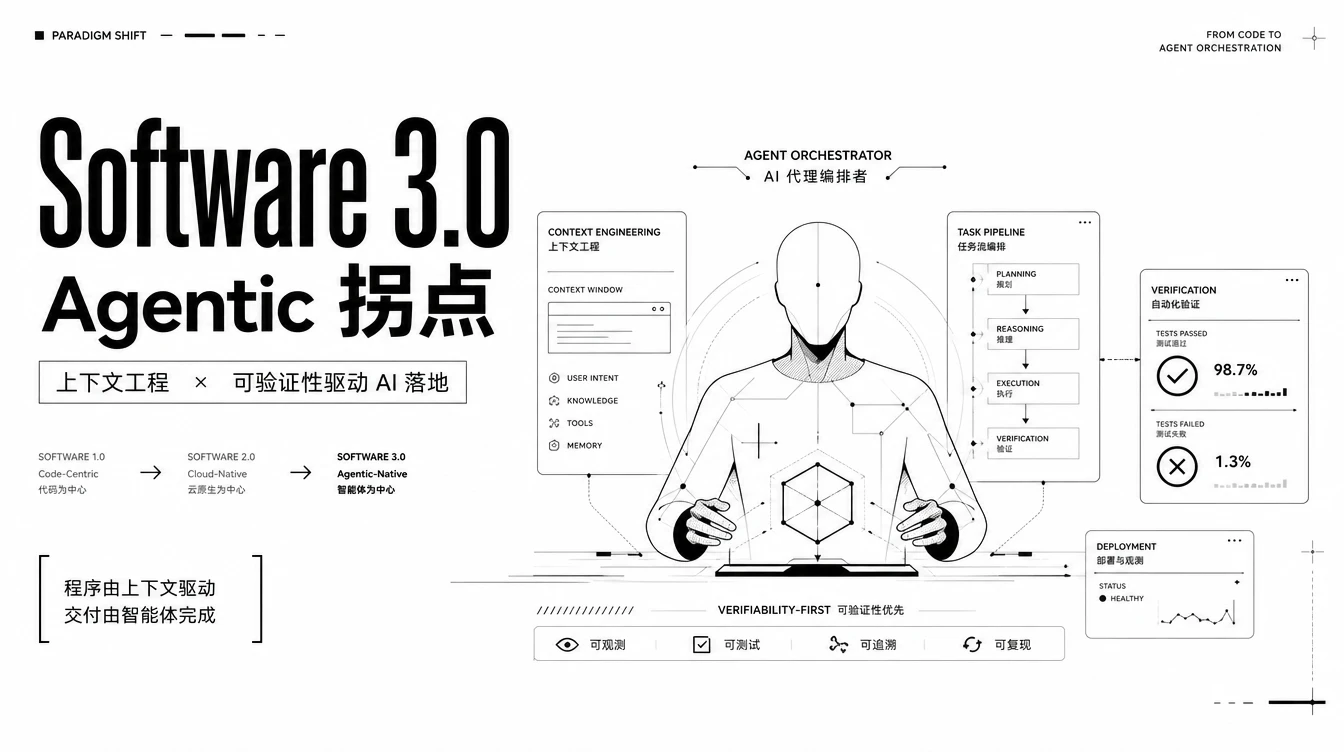
Karpathy 把这个趋势定义为 Software 3.0
1.0:人类写显式代码 2.0:人类造数据集、目标函数,程序通过权重学习 3.0:人类通过提示词、上下文、工具、示例、记忆和指令来编程 LLM
在这个范式里,Context Window 变成了主要杠杆。你给 Agent 一段指令,Agent 读取本地环境,debug 错误,适配机器,完成设置,整个过程是一个可以在任意环境中运行的"程序"。它不够精确,但足够自适应。
这其实就是"上下文工程"的本质:不是优化 prompt 的措辞,而是设计整个上下文的结构,让 LLM 作为解释器在其上执行计算。
可验证性决定了 AI 落地速度
Karpathy 给了一个核心自动化框架:
- 传统软件自动化:"你能描述清楚的东西"
- LLM 和强化学习自动化:"你能验证结果的东西"
代码为什么落地最快?因为测试会通过或失败,程序会跑或崩,diff 可以审查,benchmark 可以测量。反馈是自动化的。
这个逻辑反过来也成立:为什么很多创意类任务 AI 表现平庸?因为没有自动化的成功信号。AI 无法知道自己"做得好不好",除非你人工介入。
所以真正的问题不是"AI 能做什么",而是"你的场景是否能产生自动化验证信号"。
普通人能怎么用
如果你在用 AI 编程工具:把更大、更完整的任务丢给 Agent,不要停留在单行 prompt 层面。信任度可以更高一点了,2025 年 12 月之后的工具已经比之前可靠得多。
如果你在做 AI 产品:先问自己一个问题,我的任务是否可验证?如果答案是否定的,你可能需要人工反馈循环,或者至少是一套人工评估流程。不要指望模型自己学会"做好"一件没有奖励信号的事。
开发者值得关注的点
模型的能力不是均匀分布的。Karpathy 提出了一个公式:能力跃迁 = 可验证性 × 训练注意力 × 数据覆盖面 × 经济价值。
你的任务场景在模型的哪条轨道上?如果正好在训练密集区,模型表现会远超预期。如果不在,结果可能让人失望。这就是为什么同一个模型在不同任务上表现差异巨大。这不是模型缺陷,是训练信号分布不均的结果。