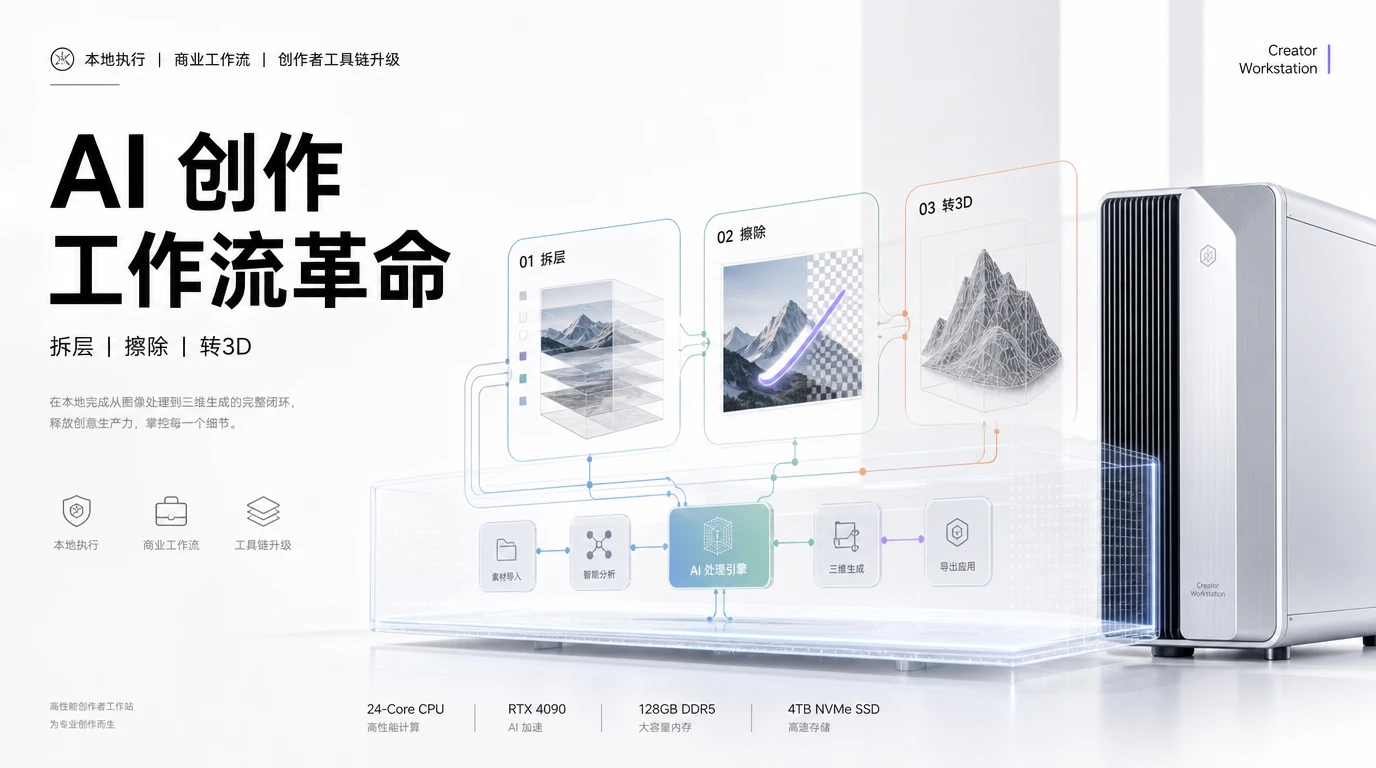
生一张好看的图容易,把 AI 出的图塞进商业工作流里难。设计师要分层PSD,视频师要干净遮罩,3D美术要可编辑模型。这些需求在Midjourney里点个按钮解决不了,在ComfyUI里以前也得自己搭节点拼半天。
4 月 30 号,NVIDIA 在官方技术博客放了一篇实操指南,配套开源了 NVIDIA GenAI Creator Toolkit。三个工作流,直接跑在 ComfyUI 里,RTX 显卡本地执行,数据不出机器。三个工作流,每一个都是创作者等了两年的东西。
第一把刀:一键拆层
上传一张照片,点 Run,输出前景、中景、背景三个 PNG,每个带透明通道。
这件事以前怎么干?在 Photoshop 里手动抠图,或者用 Remove.bg 之类的在线工具一张一张处理。商业项目里一张宣传照拆三层,十张图就是半小时的手工活。
NVIDIA 的工作流用深度估计模型自动识别画面前后关系,生成每层的遮罩,再用 inpainting 把被遮挡的区域补全。前景人物后面那块墙,AI 自动画出来。
实操要点:选景深分明的照片效果最好。人物在墙前面、产品在桌面上、建筑在天空下,这类照片拆层干净利索。纯平面构图没有景深差异,AI 读不出前后关系,拆出来就是一层。
拆完怎么用?把三层丢进 After Effects 做视差动画,前景快后景慢,一条静态照片三十秒变成短视频。或者分图层调色,改背景色不影响前景,效率比传统抠图高一个量级。
第二把刀:精准擦除
上传照片,右键打开蒙版编辑器,用白色画笔涂掉不要的物体,点 Run。涂掉的地方 AI 自动补全,和周围环境无缝衔接。
关键词是 "精准"。全局 inpainting 谁都能做,但商业场景要的是:把背景里穿帮的路人擦掉,桌面上多余的水杯删掉,产品照里反光的标签去干净。只改涂掉的部分,旁边一个像素不动。
蒙版编辑器的交互设计学的是 Photoshop 的蒙版逻辑,白色是要改的区域,黑色是保护区域。画的时候稍微比物体大一点点,给 AI 留点边距,补出来的效果会更自然。如果补出来的内容不对,可以在文字提示框里描述 "这里应该是木地板" 或者 "空白白墙",AI 会按描述生成。
这个工作流也能反向用:涂一个空白区域,描述 "放一杯咖啡",AI 会在指定位置生成匹配光照和风格的物体。拍完的场景缺道具?后期加,不用重拍。
第三把刀:照片转 3D 模型
上传一张物品照片,输出一个带纹理的 GLB 格式 3D 模型,可以直接拖进 Blender、Unreal 或者任何 3D 软件。
这把刀最重。AI 从二维图片推断三维结构,生成可旋转、可编辑的 3D 网格。工作流使用了 Meta 的 DINOv3 模型做几何推断,所以在跑之前要去HuggingFace 上登录并点击 "同意访问" Meta 的模型仓库,审批大概要一两天。
硬件门槛也是三把刀里最高的:Windows系统,RTX 24GB 显存起步,推荐 32GB 以上。磁盘空间要留 150GB 给模型文件。Linux 目前不支持这个工作流。
拍照片的技巧决定了3D模型的质量。正面或3/4角度、干净背景、物体完整可见,这三条满足就能出不错的模型。极端角度或者物体被遮挡会出破洞。
模型输出格式是 GLB,可以直接导入 Blender(File > Import > glTF),放进行游戏引擎做预可视化。不是最终成品级别的模型,但作为 layout 和 previz 的起步素材,够用了。
安装和门槛
一条命令搞定:
git clone https://github.com/NVIDIA/NVIDIA-GenAI-Creator-Toolkit
cd NVIDIA-GenAI-Creator-Toolkit
install.bat C:\path\to\ComfyUI --modules 02,03,08
02 是拆层,03 是擦除,08 是转3D。安装脚本自动下载模型、安装插件、复制工作流到 ComfyUI。首次下载模型约 150GB,网速快的半小时,慢的一小时。装完启动 ComfyUI,在 Browse Templates 里找到 NVIDIA Creative Workflows 分类,三个工作流都在。
Linux 用户把 install.bat 换成 install.sh 即可,但 08号模块(转3D)暂不支持Linux。
删起来也干净。ComfyUI 的 output 目录存生成结果,models 目录存模型,custom_nodes 目录存插件,删对应文件夹就行。也可以用 install 脚本的--clean 参数清理指定模块。
不只是三把刀:完整的创作者武器库
NVIDIA 的 GitHub 仓库里还有更多工作流在等你深入:
AI提示词增强(01):输入一个粗糙的创作描述,AI自动改写成优化后的模型提示词,并立刻生成对比图。你写"一只猫在窗台上",AI 改写成带光影、材质、构图细节的专业描述,生成结果立见高下。
360度环境生成(04):输入任意照片,生成可用于 Unreal、Blender、V-Ray 或 Arnold 的 HDRI 环境光。不需要实地采集 HDR,一张照片就够了。
灰模转电影级视频(05):给 Blender 的灰色渲染图加一张风格参考,AI 输出完整光影风格化视频。换一张风格图就是另一种风格,不用重新动画。
PBR材质管线(06):从任意图片提取纹理,自动分解为 albedo、roughness、metallic、normal、height 全套 PBR 贴图。做 3D 材质的美术可以直接出图贴模型。
安装其他模块和前面一样:
install.bat C:\path\to\ComfyUI --modules 01,04,05,06
已安装的不会重复下载。
为什么这件事值得注意
三个层面。
三把刀加上整个武器库,加上生态质变,ComfyUI 在 2026 年的定位:它不再只是 Stable Diffusion 的节点编辑器,而是 AI 创作的通用执行器。图像、视频、音频、3D 在同一个画布里流转,本地执行,数据可控。NVIDIA 的 GenAI Creator Toolkit 是这个生态里的第一批 "官方认证弹药"。
如果你的工作涉及视觉创意产出,现在是认真装一遍 ComfyUI 的时候了。不是玩玩,是把它装进你的工作流里。


