2025 年 6 月,Shopify CEO Tobi Lutke 发了一条推:“比起提示词工程,我更喜欢上下文工程这个词。”这只是一条推,不是白皮书,不是产品发布,但它一夜间炸了锅。Anthropic 紧跟着发了官方指南《Effective Context Engineering for AI Agents》,Google DeepMind 在开发者文档里用了这个说法。
有人说这是换汤不换药。他们错了。
写一条提示词让模型照做,这是提示词工程。设计一套系统,让模型在多步骤工作流的每一步都能拿到对的上下文,用对的格式,在对的时间,这完全不是同一件事。“提示词工程”从来没能描述这个范围。“上下文工程”能。
为什么是现在
三个变量同时到位了
第一,模型能力终于跟上了。GPT-3.5 时代你得哄着模型走,chain-of-thought、few-shot、格式演示,全是补丁。GPT-4o、Claude Opus、Gemini 2.0 之后,模型能可靠地遵循复杂系统指令,处理 128K+ 上下文窗口,光靠工具 schema 就能调用外部接口。当模型不再是瓶颈,瓶颈就转移到了“你给它什么信息”上。
第二,Agent 改变了游戏规则。单轮对话在生产环境里的占比正在缩小,增长点全在 Agent 上。规划多步工作流、调用工具、检索信息、跨长交互做决策。一个客服 Agent,第一轮需要用户账户历史和产品知识库,第二轮需要退款工具的 schema,第三轮需要保留处理摘要。每一轮的最优上下文都不一样。设计这种动态系统,和写一条提示词,根本不是同一维度的活。
第三,企业跑量需要管理。当 AI 部署到客服、法务、财务分析,你需要可审计、可复现、可回溯。系统指令变成版本控制的配置项,检索知识变成有文档来源和更新频率的数据管道,工具定义变成有访问控制的 API 契约。每一层都能被测试、监控、审计。你可以跟监管说“我们有文档化的上下文组装流水线”,但你不能说“我们写了一条好提示词”。
上下文工程的五层结构
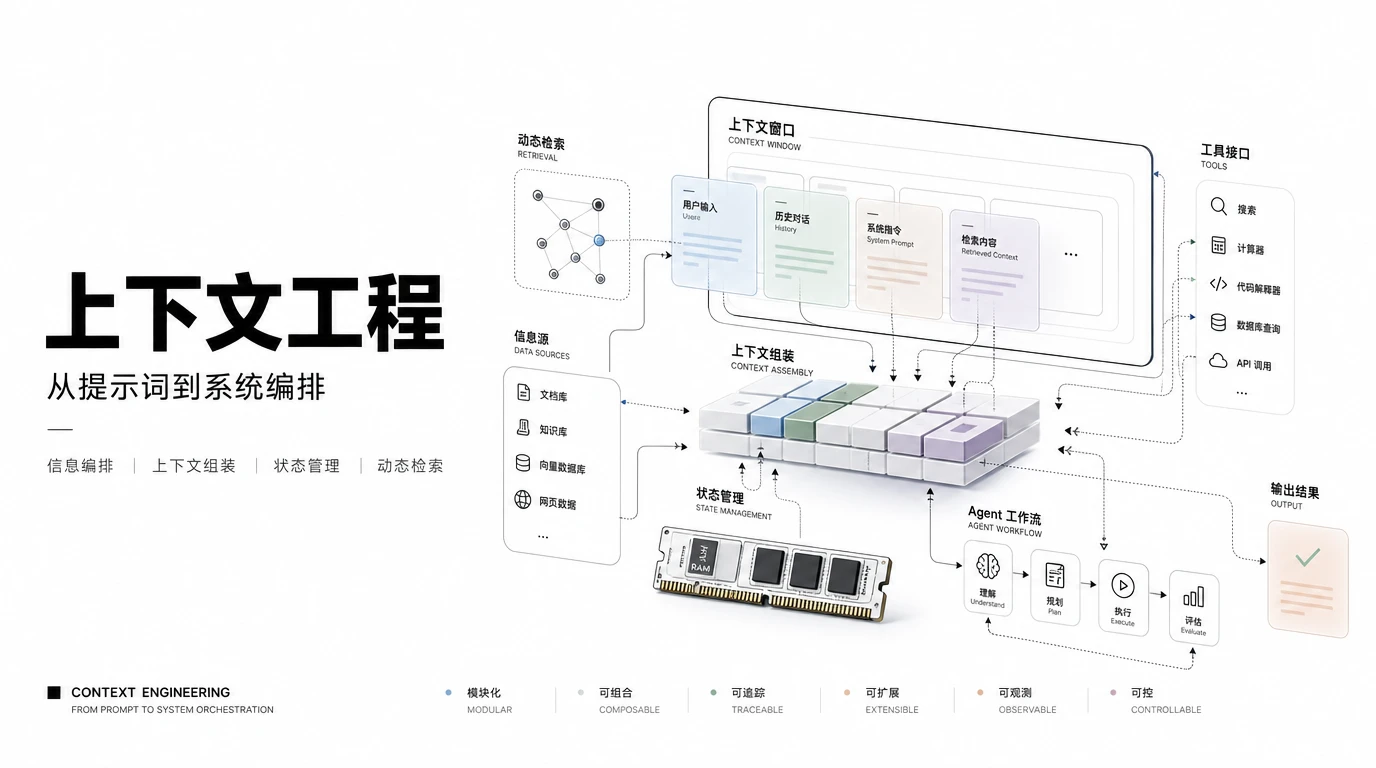
不管你有没有刻意设计,每次和 LLM 交互都涉及最多五层上下文:
- 系统指令。定义模型角色、能力和约束的基础提示词。这是最经典的系统提示词设计,依然极其重要。
- 用户输入。即时请求或查询。在提示词工程时代这是唯一的焦点,在上下文工程里它只是五分之一。
- 检索知识。推理时从外部拉取的信息:文档、数据库、API 结果。这是 RAG 所在的层,也是上下文工程和传统提示词工程区别最大的地方。
- 对话历史。先前的对话轮次、工具输出、累积状态。管理这一层意味着决定保留什么、摘要什么、丢弃什么。
- 工具定义和 schema。模型可调用的外部工具规格:函数签名、API schema、数据库查询接口。Agent 越多,这一层越是会从“没有”变成“必须”。
提示词工程师优化第一层和第二层。而上下文工程师则要设计系统来编排全部五层。
上下文窗口是 RAM,不是笔记本
Anthropic 的官方指南里有一个极其精准的类比:上下文窗口就像 RAM。有限、昂贵,不管理就会“颠簸(thrashing)”。Transformer 对每对 Token 做注意力计算,n 个 token 产生 n² 的关系对。上下文越长,模型在任意两个 token 间分配注意力的压力越大,中间位置信息的召回能力就开始退化。研究者管这叫“context rot(上下文腐烂)”。
Logic.inc 的生产级指南给出了更残酷的数据:65% 的企业,AI 系统的失败都会追溯到上下文漂移或记忆丢失,不是模型能力问题。你精心写的系统提示词,如果被 30 轮对话历史和冗余的工具输出挤到了窗口边缘,效果和没写一样。
四种上下文失败模式
- 上下文中毒(Context Poisoning):模型在某一轮产生了幻觉,下一轮把它当事实引用,错误在对话中不断放大。
- 上下文分心(Context Distraction):模型执着于一个不相关的细节,仅仅因为它出现在窗口靠前的位置。位置偏差比你想的大得多。
- 上下文混淆(Context Confusion):无关信息拉低了推理质量。更多上下文不等于更好。窗口里噪音多的时候,模型会平均掉所有信号而不是聚焦关键信息。
- 上下文冲突(Context Clash):最阴险的一种。不同轮次的指令或事实互相矛盾,模型悄悄取中间值,而不是指出冲突。
诊断这些问题的方法只有一个:在模型出错的那个时刻,检查上下文窗口里到底装了什么。
ACE 框架:让上下文自己进化
上下文工程最前沿的实践不是静态地设计上下文,而是让上下文自己进化。Agentic Context Engineering(ACE)框架是当前最成熟的方案。
ACE 要解决两个现有自改进系统的顽疾:“简洁偏见”和“上下文坍缩”。前者指系统倾向把重要细节过度压缩,最终退化为短而无用的泛泛之词。后者指系统反复重写整个提示词时,会遗忘之前积累的有用知识,导致不稳定的倒退。
ACE 的核心是一个三角色循环:
- Generator(生成器):用当前的 playbook 解决任务,标记哪些知识条目有帮助、哪些误导。
- Reflector(反思器):分析成功和失败的完整轨迹,提取可操作的教训。
- Curator(策展人):把教训转化为增量的 delta 更新,合并到现有 playbook 里。
关键设计:ACE 不维护一个单一的巨型提示词,而是把上下文组织成结构化的 playbook,每个条目是一个可复用的知识单元,带有元数据(ID、帮助次数、误导次数)和内容(策略、概念、失败模式)。增量更新,不推倒重来。定期去重,用语义嵌入去冗余。
结果如何?在基准评测上,ACE 比其他自改进上下文方法高出 +10.6%(Agent 任务)和 +8.6%(金融专业领域),token 成本降低 83.6%。
四步实操:从今天开始做上下文工程
不管你用的是 Claude Code、Codex、OpenClaw 还是自建 Hermes,以下四步是任何人都能立即上手的:
第一步:外部化状态。别把所有东西塞在上下文窗口里。Agent 应该把中间结果、计划、未解决的问题写到外部存储。测试方法:跑到第 50 轮时检查上下文窗口,如果超过一半的 token 对当前步骤没必要,说明你在积累应该外部化的状态。
第二步:按需检索。别在启动时把整个知识库灌进去。用文件路径、查询字符串、标识符作为轻量引用,需要时才拉取。只完整加载那些稳定的、始终需要的信息(流程记忆、高层指令)。按需检索那些庞大的、偶尔需要的(项目文件、历史对话、用户偏好)。
第三步:压缩累积。即便前两步做好了,上下文还是会累积。对旧对话轮次做结构化摘要(保留文件路径、错误消息、已做决策,丢弃已完成的工具输出),比暴力截断效果好得多。
第四步:隔离多 Agent。不同 Agent 处理不同子任务时,给每个 Agent 独立的上下文窗口。Agent A 的工具输出不该出现在 Agent B 的窗口里,除非 B 明确需要。
上下文工程不是提示词工程的替代品,是超集
写出清晰、结构良好的 LLM 指令依然是基本功。系统提示词设计、few-shot 示例选择、输出格式指定,这些没有变得不重要。它们变成了更大学科里的一个组件。
最准确的类比:提示词工程之于上下文工程,就像写 HTML 之于 Web 开发。好的 HTML 没有因为 Web 开发扩展到 JavaScript、数据库、API、部署流水线而变得无关。它变成了更广泛实践的基础技能。
在 2023 年,大部分的 AI 使用技巧聚焦在提示词本身:具体的措辞、结构、示例。在 2026 年,提示词依然重要,但只占生产 AI 系统工作的大约 20%。另外 80% 是检索逻辑、上下文组装、状态管理和评估。把所有这些叫做“提示词工程”,就像把整个 Web 开发叫做“写 HTML”。技术上没错,但越来越误导人。
谁控制了 Agent 的上下文,谁就控制了它的行为。谁控制了它的意图,谁就控制了它的策略。谁控制了它的规范,谁就控制了它的规模。这已经不是提示词的时代了,是工程的时代。