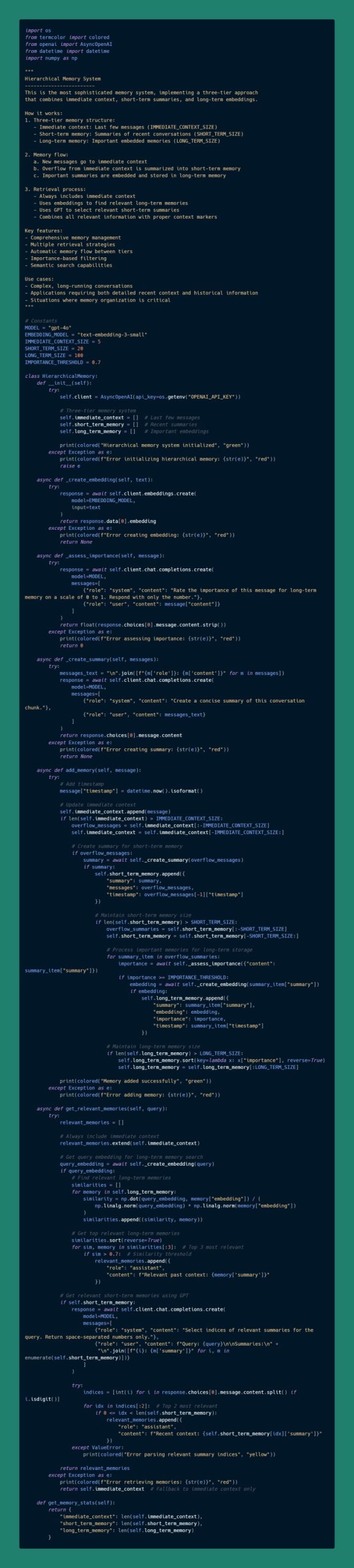
在构建大语言模型(LLM)应用时,记忆系统是提升对话上下文管理、长期信息存储以及语义理解能力的关键技术之一。一个高效的记忆系统可以帮助模型在长时间对话中保持一致性,提取关键信息,甚至具备检索历史对话的能力,从而实现更智能、更人性化的交互体验。以下是实现 LLM 记忆系统的五种方式!
- 向量记忆 (Vector Memory)
- 摘要记忆 (Summary Memory)
- 时间窗记忆 (Time Window Memory)
- 关键词记忆 (Keyword Memory)
- 层级记忆 (Hierarchical Memory)
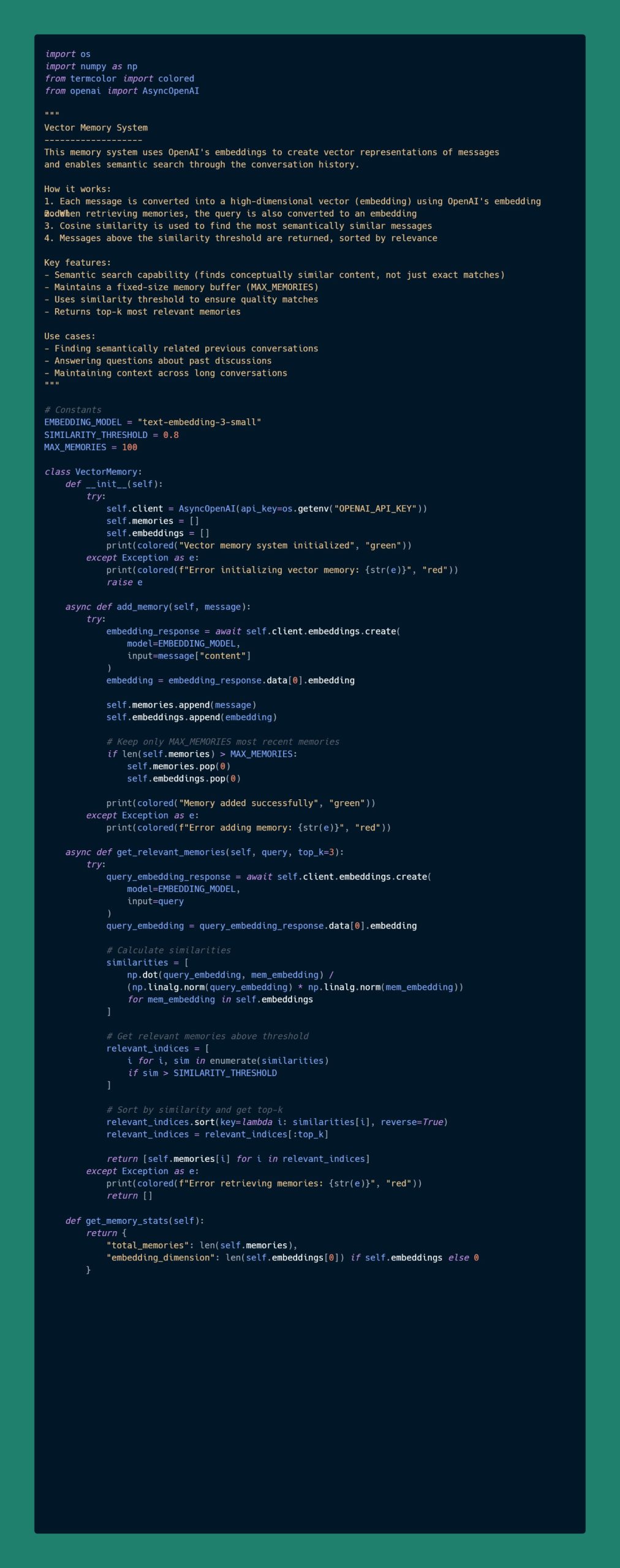
向量记忆 (Vector Memory)
概述
该记忆系统使用 OpenAI 的嵌入技术将消息转化为向量表示,并通过对话的历史记录实现语义搜索功能。
工作原理
- 每条消息通过 OpenAI 的嵌入模型转化为高维向量(嵌入)。
- 检索记忆时,将查询也转化为嵌入向量。
- 使用余弦相似度查找语义上最相似的消息。
- 超过相似度阈值的消息会按相关性排序并返回。
主要特点
- 支持语义搜索(可以查找概念上类似的内容,而不仅是精确匹配)。
- 维护固定大小的记忆缓冲区(MAX_MEMORIES)。
- 使用相似度阈值确保匹配质量。
- 返回前 k 个最相关的记忆。
应用场景
- 查找与之前对话语义相关的内容。
- 解答与过去讨论相关的问题。
- 在长对话中保持上下文一致性。
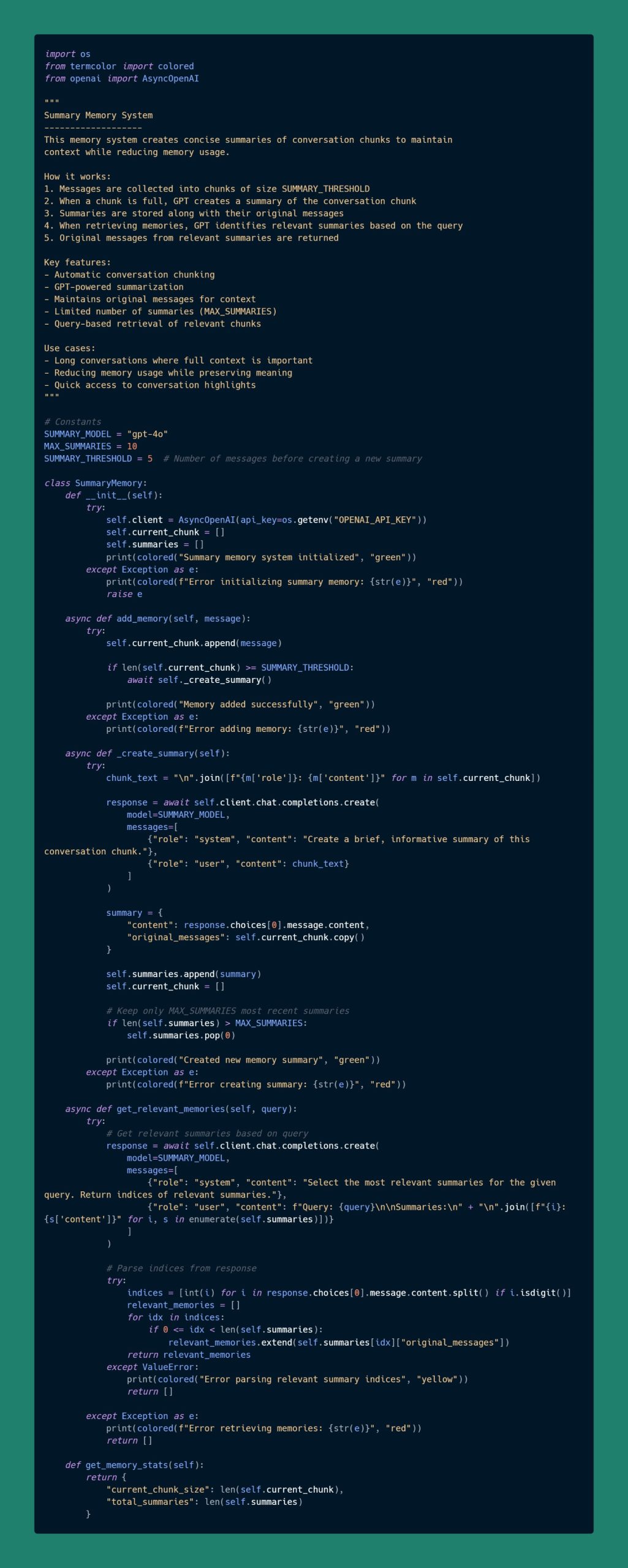
摘要记忆 (Summary Memory)
概述
该记忆系统通过为对话片段创建简洁的摘要,在减少内存使用的同时保持上下文完整性。
工作原理
- 消息被收集成大小为 SUMMARY_THRESHOLD 的对话片段。
- 当片段满时,GPT 会生成该片段的摘要。
- 摘要和原始消息一起存储。
- 检索记忆时,GPT 根据查询识别相关摘要。
- 返回相关摘要中的原始消息。
主要特点
- 自动对对话进行分块。
- 基于 GPT 的自动摘要生成。
- 保留原始消息以提供完整上下文。
- 限制摘要数量(MAX_SUMMARIES)。
- 基于查询检索相关片段。
应用场景
- 长时间对话中需要保持完整上下文的时候。
- 在保留语义的同时减少内存使用。
- 快速访问对话重点。
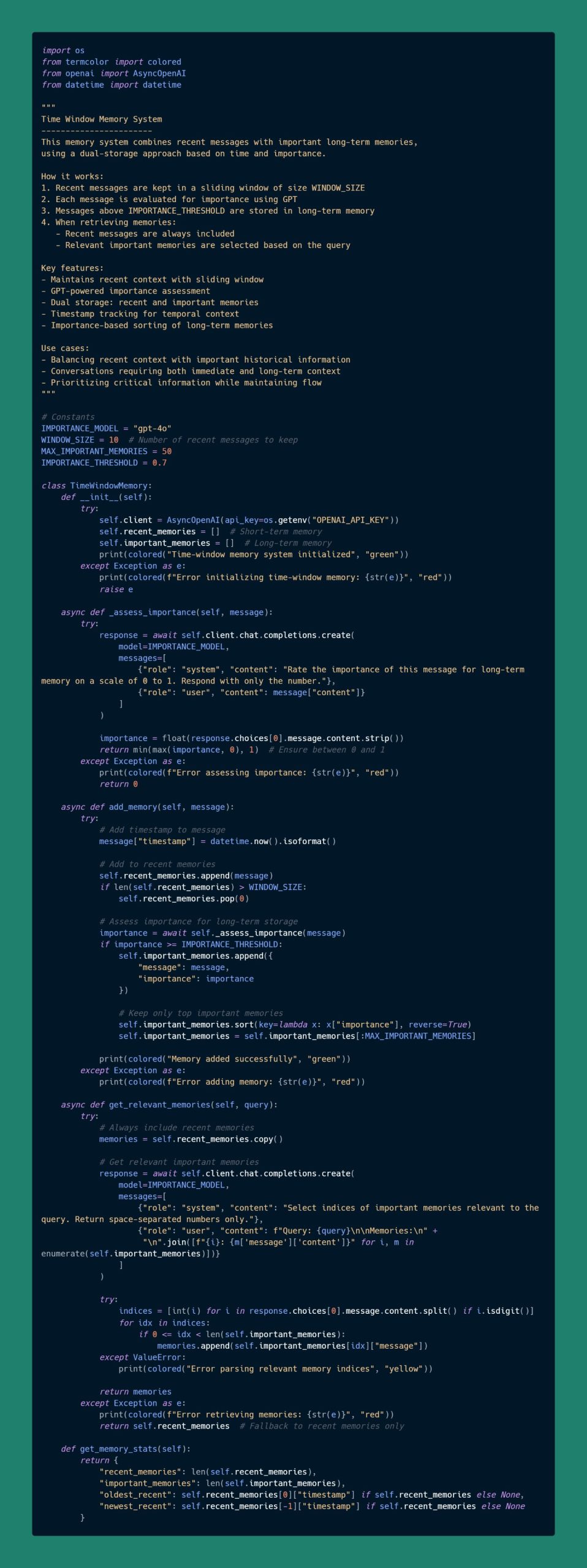
时间窗记忆 (Time Window Memory)
概述
该记忆系统结合了最近的消息和重要的长期记忆,采用基于时间和重要性的双存储方法。
工作原理
- 最近的消息保存在大小为 WINDOW_SIZE 的滑动窗口中。
- 每条消息通过 GPT 评估其重要性。
- 超过重要性阈值(IMPORTANCE_THRESHOLD)的消息存储在长期记忆中。
- 检索记忆时:
- 始终包括最近的消息。
- 根据查询选择相关的重要记忆。
主要特点
- 使用滑动窗口维护最近上下文。
- 基于 GPT 的重要性评估。
- 双存储机制:近期记忆和重要记忆。
- 时间戳追踪时间上下文。
- 长期记忆按重要性排序。
应用场景
- 平衡近期上下文与重要的历史信息。
- 需要同时考虑即时上下文和长期记忆的对话。
- 在保持流畅性的同时优先处理关键信息。
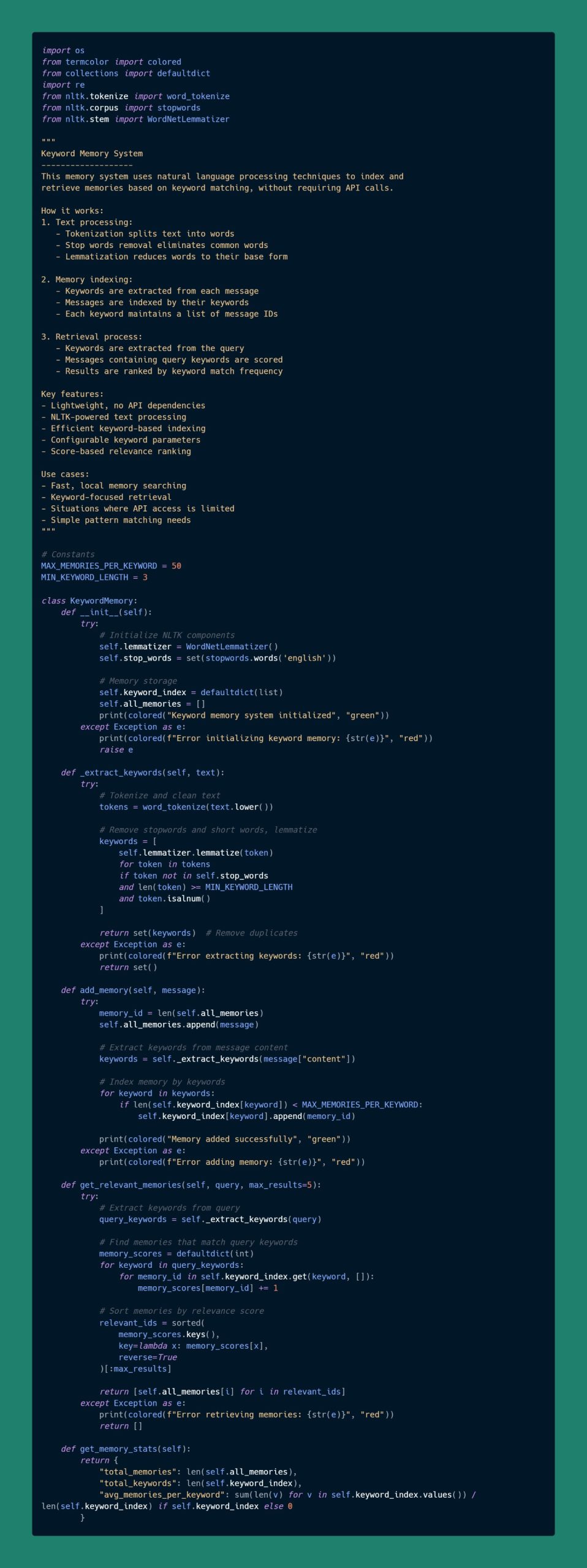
关键词记忆 (Keyword Memory)
概述
该记忆系统使用自然语言处理技术基于关键词匹配对记忆进行索引和检索,无需调用API。
工作原理
- 文本处理:
- 分词将文本分解为单词。
- 停用词移除常见无意义单词。
- 词形还原将单词还原为其基本形式。
- 记忆索引:
- 从每条消息中提取关键词。
- 消息按其关键词进行索引。
- 每个关键词维护一个消息 ID 列表。
- 检索过程:
- 从查询中提取关键词。
- 评分包含查询关键词的消息。
- 按关键词匹配频率对结果进行排名。
主要特点
- 轻量化,无需依赖 API。
- 使用 NLTK 进行文本处理。
- 高效的关键词索引机制。
- 可配置的关键词参数。
- 基于评分的相关性排序。
应用场景
- 快速的本地记忆搜索。
- 基于关键词的检索。
- 限制 API 访问时的场景。
- 简单的模式匹配需求。
层级记忆 (Hierarchical Memory)
概述
这是最复杂的记忆系统,采用三层结构,结合即时上下文、短期摘要和长期嵌入记忆。
工作原理
- 三层记忆结构:
- 即时上下文:保存最近几条消息(IMMEDIATE_CONTEXT_SIZE)。
- 短期记忆:保存近期对话的摘要(SHORT_TERM_SIZE)。
- 长期记忆:保存重要的嵌入记忆(LONG_TERM_SIZE)。
- 记忆流动:
- 新消息进入即时上下文。
- 即时上下文溢出时,转化为短期记忆摘要。
- 重要的摘要会被嵌入并存储在长期记忆中。
- 检索过程:
- 始终包括即时上下文。
- 使用嵌入技术查找相关的长期记忆。
- 使用 GPT 选择相关的短期摘要。
- 结合所有相关信息并标注上下文来源。
主要特点
- 全面的记忆管理。
- 多种检索策略。
- 自动在层级间流动记忆。
- 基于重要性的过滤机制。
- 支持语义搜索。
应用场景
- 复杂且长时间运行的对话。
- 需要同时保留近期上下文和历史信息的应用。
- 对记忆组织要求较高的场景。