#RAG

如何通过 AI 将任意文本转化为知识图谱?
无需深厚编程基础,借助Python、GPT-4o(或DeepSeek等大模型)与Neo4j,即可将书籍、新闻、维基页面等任意文本自动构建成结构化知识图谱。该方法支持多语言与复杂语境,直观呈现实体关系,显著提升语义搜索与RAG应用效果。
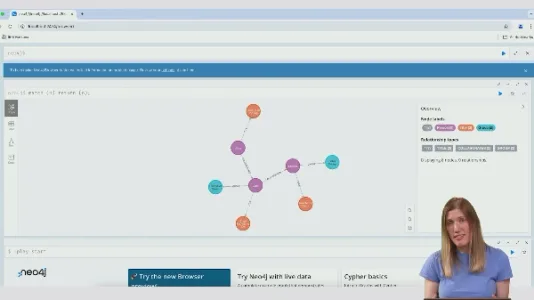
GraphRAG 知识图谱赋能智能检索:走向更强大的信息理解与推理
GraphRAG用知识图谱替代向量数据库,通过节点-边结构显式建模实体关系,显著提升复杂推理、全局归纳与多层聚合能力;大模型可自动将自然语言转为Cypher查询并解释结果,增强可解释性与检索多样性。
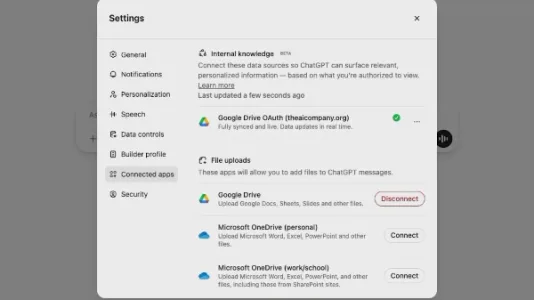
如何将通过 ChatGPT 访问和管理个人和企业内部的知识和数据
借助 Google Drive 作为知识连接器,用户可将个人或企业内部文档安全接入 ChatGPT,实现私有知识的关键词检索与交互式查询;管理员可统一管控权限,系统自动标注引用来源,便于溯源验证,提升知识复用效率与决策可靠性。

智能体 RAG:大语言模型应用的新模式
智能体RAG突破传统RAG一次性检索的局限,让大模型具备“推理-行动”能力:可基于初步结论动态调用检索工具、跨源交叉验证,实现多轮查证与迭代思考,显著提升回答的全面性与准确性。
5 个开源智能体记忆框架
RAG不是真正长期记忆,智能体需持续学习与上下文维持能力。本文推荐5个100%开源记忆框架:Graphiti(时间感知知识图谱)、Letta(白盒可调试、模型无关)、Mem0(LLM+向量存储的自适应记忆层)、Memary(自动更新的实体与偏好图谱)、Cognee(知识图谱与RAG融合的语义记忆库)。

RAG & CAG:LLM 知识增强的两种路径选择
RAG按需检索外部知识,支持海量数据与实时更新;CAG预加载知识至上下文,响应快但受长度限制。二者并非互斥,在临床决策等复杂场景中可协同使用:RAG调取病历,CAG保障对话连贯。它们代表了知识组织的两种范式,也引发对AI时代知识本质的思考。
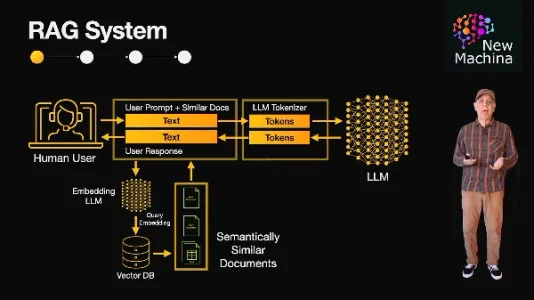
RAG 与 ReAct:两种提升大语言模型能力的关键方法
RAG通过向量检索外部知识提升回答准确性,适合专业领域问答;ReAct让模型边推理边调用工具,擅长多步骤复杂任务。二者分别拓展知识广度与推理深度,可独立使用或协同集成,是构建实用AI应用的关键路径。

Graph RAG:知识图谱让 AI 回答更聪明
IBM提出的Graph RAG在传统RAG中引入知识图谱,让AI能像人类专家一样建立知识点间的语义关联,实现深度理解与推理。它不只检索答案,更能整合分散信息、给出全面建议,在医疗、金融等高要求领域兼顾响应速度、可维护性与权限管控。

RAG 和 模型微调哪个好,怎么用?
RAG借助外部向量库实时检索信息,成本低、易更新,适合需动态数据的场景;模型微调则通过领域数据训练提升专业性与准确性,但耗资源且知识静态。二者并非互斥,常结合使用——RAG补时效,微调强专精。