大多数人用 AI 的方式是把所有要求塞进一条提示词里,然后祈祷输出能对。短任务还行,稍微复杂一点就崩:数字对不上、逻辑跳步、格式乱套。你以为是模型不行,其实是你的调用方式不对。
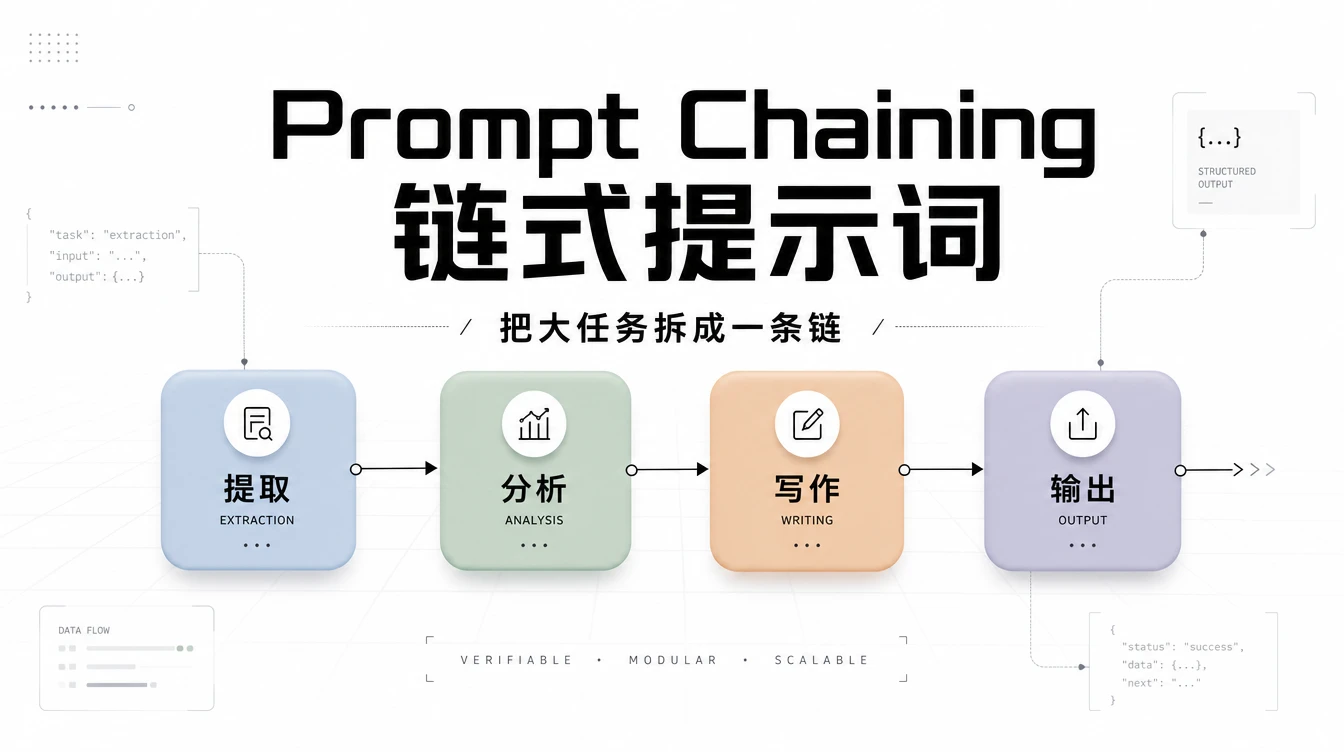
Prompt Chaining 的思路很简单:把一个大任务拆成几个小步骤,每一步的输出喂给下一步当输入。不是一条提示词搞定一切,而是一条链搞定一切。
为什么一条提示词不够用
先说清楚问题。单条提示词处理复杂任务时,会撞上四堵墙。
第一堵墙:上下文溢出。AI 的工作记忆是有限的,把一份 40 页的年度报告扔进去,要求它同时提取数据、分析战略、写简报,模型到后半段就开始忘事。前面提取的数字,写到结论时已经对不上。
第二堵墙:错误累积。一条长提示词里,推理的第二步如果算错了,第三步、第四步全部跟着错,而且你没法在中间拦住它。就像电子表格里一个单元格写错了公式,后面所有引用这个单元格的结果全废。
第三堵墙:职责混杂。提取、分析、写作是三种完全不同的能力。让一个模型同时做这三件事,等于让一个人边读财报边写PPT边回答老板提问,哪件都做不好。
第四堵墙:无法校验。单条提示词跑完,你只看到最终结果,中间过程是个黑箱。提取的数字对不对?分析有没有偏差?你不知道,只能盲审。
Prompt Chaining 解决的就是这四个问题。每一步只做一件事,做完你能检查,检查过了再把结果喂给下一步。
三种核心链模式
链式调用不是一种模式,是三种。用错模式比不用还糟。
模式一:顺序链。最简单的形式,A→B→C,每步的输出是下步的输入。适合有天然线性顺序的任务。
举一个竞争分析的案例。小张需要在周一前分析竞争对手 40 页的年度报告,提取关键财务数据,判断战略意图,写一份高管简报。他一开始把所有要求塞进一条提示词,得到的简报数字模糊、分析肤浅、格式随意,周末全花在修补上。
他的同事小陈用三条链式提示词完成。第一步提取:告诉模型 "你是财务分析师,从这份报告中提取近三年营收和利润数据、CEO 提到的三大战略优先级、新产品和市场扩张、风险和挑战,输出为结构化 JSON"。第二步分析:把第一步的 JSON 喂给模型,"你是竞争战略顾问,基于这些数据判断对我司最大的三个威胁和两个机会"。第三步写作:把分析结果喂给模型,"你是管理顾问,基于这份战略分析写一份两页高管简报,开头放最重要的结论,列出三个威胁两个机会并附具体证据,结尾给三个行动建议。语气直接果断,禁止套话。"
结果差异在哪?第一步只管提取,模型把全部注意力放在数字准确性上。第二步拿到的不是原始 40 页报告,而是干净的结构化数据,分析精度自然高。第三步拿到的不是夹杂着原始数据的推理过程,而是清晰的战略判断,写作质量直接上台阶。
模式二:条件路由链。先分类,再分流。第一步判断输入属于什么类型,然后走不同的处理链。适合客服、内容审核、意图检测等场景。
客服系统的实际部署长这样。第一条提示词做分类:"将这条客户消息归入以下类别之一:账单问题、程序缺陷、登录问题、新功能建议、流失风险、常见问题。只输出类别名。"分类结果决定走哪条分支。
如果分类结果是“程序缺陷”,走技术支持链:"你是一线技术支持,确认具体问题,用通俗语言解释原因,给出三个排查步骤,告诉用户不行的话怎么办。200字以内。"如果分类结果是“流失风险”,走挽留链:"你是客户成功经理,真诚理解用户不满,问一个澄清问题了解真正原因,提及一个他们实际使用过的功能价值,给出适当的解决方案。不要强推。"
关键是:账单投诉永远不会收到挽留话术,退订风险永远不会收到排障清单。路由步骤就是智能本身,专业化的分支链就是专长。
模式三:并行链。多个 AI 调用同时跑,各管一个维度,最后合并结果。适合需要多角度分析的研究任务。
分析一家公司时,你可以同时发起三个调用:一个分析财务健康度,一个评估技术竞争力,一个审查法律和合规风险。三个调用并行跑完,最后一条提示词把三个维度的分析综合成一份整体评估。
并行链的优势是速度。三个5秒的调用并行跑,总共只花 5 秒加一次合并调用的时间,而不是串行的 15 秒以上。
实操模板:从零搭建你的第一条链
假设你要分析一份产品用户反馈报告。
链节点1(提取):"你是数据分析师。阅读以下用户反馈,提取每条反馈的核心问题、情感倾向(正面/中性/负面)、涉及的产品模块。输出为 JSON 数组,每个元素包含“文本摘要”、“情感分析”、“模块”三个字段。"
链节点2(分类聚合):"你是产品经理。基于以下结构化反馈数据 [插入节点 1 输出],按产品模块分组统计,计算每个模块的负面反馈占比。输出三列:模块名、负面反馈数、负面占比。按负面占比降序排列。"
链节点3(建议):"你是产品总监。基于以下模块级反馈统计 [插入节点 2 输出],针对负面占比最高的三个模块,各给出一个具体改进方案,包含目标、关键行动和预期效果。"
三条提示词,各自只做一件事。你可以在每个节点停下来检查输出,发现哪步有问题直接重跑那一步,不用从头来。
避坑指南
链式调用最常见的三个坑。
第一,信息衰减。链越长,到后面节点保留前面信息的能力越弱。解法是:每个节点的提示词里只放它需要的信息,不要把全部历史都传下去。第三步不需要看原始 40 页报告,只需要看第二步的分析结论。
第二,格式不兼容。节点 1 输出的是一段文字,节点 2 期望的是 JSON,链就断了。解法是:每个节点的提示词明确指定输出格式,并在下个节点的提示词里声明输入格式。格式是节点之间的接口协议,必须提前设计。
第三,过度链化。三步能搞定的事不要拆成十步。每多一步就多一次API调用成本、多一个潜在失败点、多一份中间输出要审核。我自己的原则:能一条提示词搞定的任务(比如翻译一段话),不要链化。需要两种以上不同能力(提取+分析+写作)的任务,链化收益明显。五步以上的链,考虑是否某些步骤可以合并。
成本账
链式调用会增加 API 调用次数,但每次调用的 Token 数更少、输出质量更高。实际算下来,总 Token 消耗可能持平甚至更低,因为每步的提示词更短更精确,不用在一个超大提示词里塞大量上下文。
以竞争分析为例:一条超大提示词可能需要 4000+ Token 的输入,输出 2000 + Token 但质量参差不齐。三条链式提示词,每条输入 800 到 1200 Token,输出 500 到 800 Token,总输入约 3000 Token,总输出约 1800 Token,但每个输出都是高精度。总成本可能相当,但审核和返工成本大幅下降。
工具选择
手动复制粘贴也能跑链,但生产环境需要自动化。几个选择:
LangChain 是最成熟的框架,支持所有链模式,文档丰富,但学习曲线陡。DSPy 更学术化,自动优化提示词,适合研究场景。OpenAI 的 Agents SDK 原生支持 handoff 机制,相当于内置了条件路由链。Anthropic 的 Programmatic Tool Calling 可以批量并行调用,天然适合并行链模式。国内的话推荐字节的扣子。